https://developer.arm.com/documentation/102376/latest/
https://developer.arm.com/documentation/101811/latest
책은 ARMv7과 ARMv8 양쪽 모두를 다루고 있습니다.
이미 이전 포스트들에서 ARMv7에 대해서 충분히 공부했기 때문에, 이번 포스트에서는 ARMv8에 집중해서 다룹니다.
ARMv7 관련 내용 중 일부는 해당 내용을 자세히 다룬 포스트를 주석으로 링크 달고 생략하도록 하겠습니다
10. 메모리 모델
10.1. 노멀 메모리와 디바이스 메모리

ARM 아키텍처에서는 메모리를 두 가지 종류로 분류합니다.
Memory mapped I/O를 위해 할당하는 메모리 영역을 '디바이스 메모리', 그외 모든 영역을 '노멀 메모리'라고 합니다.
컴파일러는 최적화를 위해 사용자가 작성한 코드에 다양한 최적화 기법을 적용합니다. 큰 도움을 주지만, 때로는 의도를 갖고 작성한 코드임에도 순서를 멋대로 바꾸거나 멋대로 코드를 삭제해 문제를 일으키곤 합니다. 따라서 적어도 디바이스 메모리 관련 코드만큼은 이런 최적화가 발생하지 않도록 해야합니다.
ⓐ Merge Access
메모리 접근횟수를 한 번이라도 줄이기 위해, 연속된 메모리에 접근하는 명령어의 경우에는 한 번에 처리하는 기법입니다.
ⓑ Speculation
다음 번에 접근할 것으로 예상하는 데이터를 패턴 인식같은 알고리즘을 활용해 미리 예측해 로딩하는 기법입니다. 분기예측, 실행예측 등이 여기에 포함됩니다.
ⓒ Re-ordering Access
- 명령어 간 의존성이 없다면 파이프라인과 메모리 접근이 덜한 유리한 방향으로 명령어의 순서를 바꿔서 처리하는 기법입니다. (의존성 = Data Hazard = 명령어 피연산자에 접근하려는데, 이전 명령어들의 수행이 끝나야만 올바른 값을 얻을 수 있음)
- Memory mapped I/O는 특정 동작을 위해 순차적으로 접근해 페리퍼럴을 제어하는 루틴으로 이루어져있기 때문에 명령어 순서가 바뀌면 원하는대로 동작하지 않습니다.
- 따라서 노멀 메모리에서 사용하던 최적화 기법을 디바이스 메모리에 적용하면 안됩니다.
10.2. 메모리 배리어 (DMB, ISB, DSB)
임베디드 프로그래밍에서 '이 변수에 대해서는 멋대로 최적화를 하지 말아주세요'라는 용도로 컴파일러가 알아볼 수 있도록 `volatile` 키워드를 사용하곤 합니다. 마찬가지로 컴파일러가 멋대로 최적화기법을 사용해서 디바이스 메모리에 접근하는 memory mapped I/O 코드부분에 문제가 생기지 않도록 '메모리 배리어'라고 하는 것을 사용할 수 있습니다.
메모리 배리어에는 DMB, ISB, DSB 3가지 종류가 있습니다.
① DMB (Data Memory Barrier)
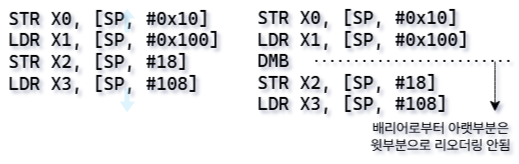
DMB는 리오더링 액세스를 방지하는 배리어입니다. 배리어를 사용한 이후 명령어들은 배리어로 보호되고 있는 배리어 이전 명령어들 쪽으로 리오더링 되지 않습니다. 이때, 리오더링 방지는 오직 로드 스토어 명령어 (LDR, STR)에만 적용됩니다. DMB는 메모리/ 레지스터 의존성에 대해서만 보호하기 때문입니다.
② ISB (Instruction Synchronization Barrier)
ISB는 명령어 스트림의 동기화를 보장하는 배리어로, ISB 명령어 이전의 모든 명령어 실행이 완료된 후에야 이후의 명령어를 실행하도록 합니다. 주로 명령어 캐시나 TLB와 관련된 변경 사항을 적용하는 데 사용됩니다.
③ DSB (Data Synchronization Barrier)
위 두 배리어보다 강력한 배리어로, DMB + ISB라고 생각하면 됩니다. 데이터 메모리 접근뿐만 아니라 캐시, 분기예측과 관련된 모든 메모리 시스템 동작의 완료를 보장합니다. 즉, DSB 배리어 이후 명령어는 마치 이전에 실행하던 명령어가 없던 것처럼 깔끔한 상태로 시작합니다. 단, DSB 명령어는 아주 강력한만큼 성능면에 큰 영향을 미치기 때문에 남용하면 안됩니다.
10.3. 메모리 배리어 사용 케이스 스터디
1. 멀티코어 시스템에 적용하는 메모리 배리어

공통자원 전역변수 'mailbox'에 두 CPU 코어가 접근하고 있습니다.
CPU0이 mailbox에 데이터를 쓴 뒤 'box_flag'라는 플래그변수를 '1'로 set 하면 CPU1이 읽습니다.
상황 ① - CPU0에서 명령어 리오더링 발생
CPU0에서 명령어 리오더링이 발생하면, mailbox에 값을 쓰기도 전에 먼저 box_flag를 set 하게 됩니다. 따라서 CPU1은 mailbox에서 자칫 잘못된 값을 읽을 수 있게됩니다.
상황 ② - CPU1에서 명령어 리오더링 발생
상황 ①을 막기 위해 CPU0에 DMB 명령어를 사용해서 리오더링을 막았습니다. 그러나 이번엔 CPU1에서 리오더링이 발생했습니다. box_flag 값을 확인하지도 않고 mailbox를 읽기 때문에 잘못된 값을 읽을 수도 있습니다.
▶ 결론: 공유자원을 사용할 떄는 생산자든 소비자든 양쪽 모두 배리어를 사용해야 합니다.
2. 리눅스 커널 :: 스핀락 해제 시 배리어

DMB 배리어 덕분에 인라인 어셈블리로 작성한 부분은 다른 곳으로 리오더링 되지 않습니다.
또한, DSB 배리어 덕분에 다른 명령어들이 인라인 어셈블리 사이로 리오더링 되는것을 방지하며,
이후 명령어를 실행하기 전 '반드시' 인라인 어셈블리 실행을 마칠것을 보장합니다.
3. 리눅스 커널 :: 시스템 레지스터 설정 시 ISB 배리어

MMU를 셋팅하면서 페이지 테이블의 base 주소 TTBR0_EL1, TTBR1_EL1 레지스터값을 설정하는 코드입니다. 각 시스템 레지스터를 설정할 때는 중간에 방해받지 않도록, 시스템 레지스터 값 수정이 온전히 끝날 때까지 기다리도록 ISB 배리어를 사용합니다.
11. 캐시
11.1. 캐시란

※ 배경
CPU 코어보다 상대적으로 느린 메모리 속도 때문에, 메모리의 접근 할 때마다 병목현상이 발생합니다.
CPU 코어와 메모리 사이에 저용량이더라도 속도가 빠른 임시메모리 저장장치가 있으면 좋겠다는 수요가 발생합니다.
이에 최근 사용한 명령어와 데이터를 저장하는 아주 빠른 메모리 (캐시, Cache)를 뒀더니 전체 시스템 성능이 크게 증가하게 됩니다.
(위 그림의 Level 1, 2 Cache)
※ 원리
캐시 메모리의 동작원리를 아주 간단명료하게 표현하면 '지역성(Locality)의 이용'입니다.
지역성은 ⓐ 공간지역성 (Spatial Locality)과 ⓑ 시간지역성 (Temporal Locality)로 ⓒ 알고리즘 지역성(Algorithm Locality)으로 나뉩니다.
공간지역성은 다음 번에 메모리 접근할 때는 이전에 접근했던 주소 근처에 접근할 '가능성'이 높다는 특성을 의미합니다.
- 배열 같은 것을 생각해보세요.
- 처음 보는 메모리 영역의 주소에 접근했다면, 해당 주소 데이터 뿐만 아니라 인근 메모리 영역을 함께 캐시라인으로 가져옵니다.
- 그렇다면, 굳이 메모리에 접근하지 않더라도 캐시라인 속에서 원하는 데이터를 찾을 '가능성'이 높습니다.
시간지역성은 한 번 접근한 메모리 주소는 다시 접근할 가능성이 높다는 특성을 의미합니다. 반복문 같은 것을 생각해보세요.
알고리즘 지역성은 메모리상 연속되진 않았더라도, 자료구조 상 다시 접근할 가능성 높은 특성을 의미합니다. 연결리스트를 떠올려보세요.
즉, 메모리 접근 횟수를 한 번이라도 줄여서 전체 시스템 성능 향상을 꾀하는 매커니즘이 캐시입니다.
캐시 히트 (Hit): 캐시 속에서 요청받은 데이터를 찾아내는 것
캐시 미스 (Miss): 찾지 못한 것
11.2. 캐시 구조

일반적으로 캐시는 위 그림과 같이 계층구조로 이루어져있습니다.
즉, 단독 단일 캐시로 운용하지 않고, 적어도 두 개 이상의 level로 나뉜 캐시를 운용합니다.
- 가장 아랫계층인 Level 1 Cache는 하버드 아키텍처를 적용해 명령어만 저장하는 Instruction cache와 데이터값만 저장하는 Data cache로 나뉘어 각 코어마다 존재합니다.
- 그보다 조금 더 크면서 여러 코어가 같이 사용하는 캐시인 Level 2 Cache (L2$)가 있습니다.
- 그보다 더욱 크면서 여러 클러스터가 같이 사용하는 캐시인 Level 3 Cache (L3$)가 있습니다.

지금부터 프로세서가 어떤 메모리 주소(가상주소)에 접근을 요청했을 때, 캐시를 어떻게 활용하는지 보겠습니다.
먼저, 주어진 가상주소를 물리주소로 변환한 후 캐시에서 원하는 데이터를 찾는 과정을 캐시 룩업(look-up)이라고 합니다.
주소는 Tag, Index, Offset 세 가지 파트로 나뉩니다.
- Tag: 주소의 상위 부분입니다. 바로 아래에서 설명하겠지만, 위 그림에서 'Set'은 같은 index값을 가지는 캐시라인 집합을 의미하는데, 여기서 어떤 캐시라인이 CPU가 찾는 캐시라인인지 식별하는 용도로 사용합니다. 이렇게 tag들만 모아둔 곳을 Tag RAM (태그램)이라 합니다.
- Index: 주소의 중간 부분입니다. 배열의 인덱스처럼 캐시의 특정 인덱스, 특정 캐시라인을 가리키는 용도로 사용합니다. 캐시라인에는 메모리에서 가져온 raw data가 들어있으며 64 또는 128바이트로 구성돼있습니다.
- Offset: 주소의 하위 부분입니다. 캐시라인 속에서 원하는 데이터를 가리키는 용도로 사용합니다. 64-bit 주소에서는 2⁶, 6-bit를 가집니다.
Q. 캐시에서 인덱스로 캐시라인을 찾고, 태그값을 비교하고, 오프셋으로 데이터를 찾는 흐름인데 왜 주소의 중간부분을 인덱스로 설정했을까요?
A. 공간지역성을 고려했을 때, 상위주소는 잘 안 바뀌기 때문입니다. 만일 상위주소를 인덱스로 설정했다면, 같은 인덱스를 갖는 캐시라인들이 계속 충돌을 일으켰을겁니다. 그래서 캐시 성능을 최대한으로 끌어올릴 수 있도록 주소 중간부분으로 설정합니다.
캐시에는 해당 캐시라인의 속성을 나타내는 부가정보 bit들도 있습니다.
대표적으로 캐시라인과 맵핑되는 태그정보, V(Valid)-bit, D(Dirty)-bit 입니다.
- V-bit (Valid): 해당 캐시라인의 데이터가 유효한지 여부를 나타냅니다.
- D-bit (Dirty): 해당 캐시라인의 데이터가 수정됐는지 여부를 나타냅니다. 프로세서의 메모리 접근을 최소화하기 위해 캐시정책에 따라 값을 메모리에 쓰지 않고 캐시에만 쓰는 경우가 있습니다. 이런 경우에는 캐시라인의 데이터 ≠ 해당하는 메모리의 데이터이므로 dirty bit를 set 해줘서 modify 됐음을 표시합니다.
11.3. 캐시 과정과 Set-Associative
캐시 속에서 원하는 데이터를 찾는 과정은 다음과 같습니다.
1. 주소의 'Index' 부분에 해당하는 캐시라인을 찾습니다.
2. 해당 캐시라인과 맵핑되는 태그를 TagRAM에서 찾고, 주소의 'Tag' 부분과 비교합니다.
3. 같다면 캐시 히트, 다르면 캐시 미스입니다.
캐시 미스가 발생했다면, 해당 캐시라인은 'victim'으로 표시되며
캐시정책에 따라 추후 메모리 접근 후 새로운 데이터를 가지고 와 victim 표시된 캐시라인을 새로운 라인으로 교체합니다.
이 과정을 eviction이라고 합니다.

위에서 봤던 캐시라인의 묶음이 이번에는 2개 있습니다.
위 그림과 같이 캐시라인의 묶음을 여러 개 두는 것을 'way'라고 하며 같은 인덱스의 캐시라인들은 'set'이라 합니다.
- 주소가 발생했는데, 인덱스가 0이네요.
- 각 캐시 way의 0번 set (0번 인덱스 캐시라인들)을 찾습니다.
- 이제 태그를 비교해서 두 캐시라인 중 어느 캐시라인이 타겟인지 판단하면 되겠습니다.
이런 set-associative 구조의 캐시를 사용하는 이유는 조금이라도 캐시 히트율을 높이기 위해서입니다.

ARM의 Set-Associative 캐시 구조를 나타낸 그림입니다.
- 캐시라인 묶음이 4개가 겹쳐져있는것을 보아하니 4-way set associative 캐시입니다.
- 한 캐시라인 묶음 당 캐시라인은 총 256개 있습니다. 주소의 index 부분도 [13:6]으로 8-bit로 돼있네요.
- 하나의 캐시라인을 주소의 offset 부분 [5:2] bit로 표현하니 2^4 = 16-word = 64바이트가 캐시라인의 크기입니다.
캐시 크기를 계산해보면, (캐시라인 크기) * (캐시라인 개수) * (way 수, set 수) = 2^6 * 2*8 * 4 = 2^16 = 64KB
즉 64KB 4-way set associative L1 캐시인것을 알 수 있습니다.
(참고로 최근 캐시는 모두 물리주소를 이용합니다. 11장 제일 첫 그림을 보세요. L1, L2 캐시에 가는 주소는 페이지 테이블로부터 나오는 물리주소인것을 알 수 있습니다. 이러한 구조를 PIPT(Physical addr Index, Physical addr Tag라고 합니다. 예전에는 VIPT를 썼다고 합니다.)
11.4. 캐시 정책
멀티 캐시 정책
L1, L2, L3 다단계 계층구조로 돼있는 캐시에게는 '유효한 캐시를 어떻게 관리할지'에 대한 규칙이 필요합니다.
예를 들어
- 상위 계층 캐시와 하위 계층 캐시는 데이터를 중복해서 저장할 것인가?
- 만일 중복을 허용하지 않는다면, 중복 발생 여부를 어떻게 판단할 것인가?

경우에 따라 Inclusive, Exclusive, Non-inclusive 세 가지 정책으로 나뉩니다.
먼저 inclusive의 경우, 각 캐시가 갖고 있는 정보는 중복될 수 있습니다.
- L1에서 발견했을 경우 바로 쓰면 되고,
- L1에 없는데 L2에서 발견했을 경우, L1으로 가져오는데 L2에도 그대로 남겨둡니다.
- L1, L2 모두 없는 경우, 메모리에 접근해서 데이터를 가져오는데, L1, L2 모두 가져옵니다.
하지만 exclusive의 경우 중복을 절대 허용하지 않습니다.
Non-inclusive는 위 두 정책을 적당히 합쳐놓은거라고 합니다.
일반 캐시 정책
지금까지 캐시를 '읽는 경우'만 생각했지만, 읽은 값을 '쓰는 경우'도 생각해보면 새로운 의문이 생깁니다.
- 갱신된 값을 어디까지 적용하는게 좋을까요?
- 캐시에만 적용할까요? 아니면 원본이 있는 메모리까지 적용해야 할까요?
캐시에 적용된 캐시 정책에 따라 달라집니다.
Write Through: 캐시 뿐만 아니라 메모리에도 갱신된 데이터를 반영합니다. 이 정책은 캐시와 캐시 그리고 캐시와 메모리 사이의 일관성을 유지합니다만, 성능 면에서는 손해를 봅니다.
Write Back: 갱신된 데이터는 캐시에만 적용됩니다. 데이터 일관성이 깨질 수 있습니다만 성능면에서는 탁월합니다. 일관성 문제를 해결하기 위해 'write buffer'를 따로 마련한 뒤 이곳에 갱신된 데이터를 적어놓고, 버퍼가 꽉 찼을 때 메모리에 한 번에 bulk로 저장하는 방식을 사용합니다.
이외에도 L1 캐시처럼 각 코어마다 캐시를 갖고있는 경우에는 각 코어마다의 데이터 일관성이 이슈가 됩니다.
이때는 캐시에 캐시라인을 저장하고 eviction 하는 과정에 MESI, MOESI 프로토콜을 적용해서 해결합니다.

11.5. 캐시 성능지표
캐시의 성능은 단순히 캐시 히트율과 캐시 미스로 결정되지 않습니다.
정량적인 캐시 성능은 평균 접근시간 = ① Hit latency + ② Miss ratio의 합으로 결정됩니다.
- Hit latency: 캐시에서 데이터를 코어로 가져올 때 소요되는 시간
- Miss ratio: 전체 캐시 접근 횟수 중 miss 발생 비율
- Miss panelty: 캐시 miss 발생 시 캐시라인 eviction 후 코어가 올바르게 값을 받기까지 걸리는 시간
특히 hit latency와 miss ratio는 서로 trade-off 관계에 있습니다.
- 캐시 사이즈를 무작정 크게 키웠다고 가정합시다. Way도 잔뜩 늘리고 캐시라인 개수와 길이도 잔뜩 늘렸습니다.
- 분명히 이러면 캐시 miss가 발생할 확률은 현저히 낮아집니다.
- 그러나, 올바른 캐시라인을 찾기 까지 소요되는 시간이 늘어나고 (탐색시간 증가)
- 캐시 hit이 발생해도 코어로 가져와야하는 데이터양이 증가합니다.
- 결과적으로 hit latency가 높아집니다.
- Hit latency를 낮추기 위해 way도 줄이고 캐시 구조를 아주 단순히 만들면 어떨까요?
- Direct-mapped 캐시는 인덱스 당 하나의 캐시라인만 있을 수 있기 때문에 아주 낮은 hit latency를 가지지만,
- 그만큼 충돌로 인한 collision miss가 많이 발생해서 캐시라인 eviction이 자주 일어납니다.
- 결과적으로 메모리에 더 많이 접근하게 돼 miss ratio와 miss panelty 모두 높아집니다.
일반적으로
- CPU와 굉장히 빈번하게 명령어와 데이터를 주고받는 L1은 hit latency를 줄이는게 중요합니다. 그래서 20년 전 ARM11 프로세서와 현재 프로세서의 L1 캐시 크기가 거의 차이가 없는 것입니다. (약 64KB)
- L2, L3는 최대한 메모리 접근 횟수를 줄이기 위해 miss ratio를 줄이는게 중요합니다.
11.6. 캐시 제어 레지스터
CTR_EL0 레지스터

캐시 아키텍처의 정보를 설정하고 현재 캐시가 어떻게 구성돼있는지 정보를 알려주는 레지스터입니다.
DminLine, IminLine에서 L1D$와 L1I$의 캐시라인 크기가 몇 바이트인지 알 수 있습니다.
L1Ip는 L1$의 캐시정책을 알려줍니다.
CLIDR_EL1 레지스터

Ctype1~7이 있는데, 각각 3-bit씩 할애해서 각 캐시 레벨의 구현방식을 설정합니다.
- `0b000`: 캐시 사용 안 함
- `0b001`: 명령어 캐시만 사용
- `0b010`: 데이터 캐시만 사용
- `0b011`: 명령어 캐시 + 데이터 캐시 이용 but 분리
- `0b100`: 명령어 캐시 + 데이터 캐시 이용 but 통합
12. 메모리 매니지먼트 (MMU)
12.1. MMU란?

MMU (Memory management unit)은 가상주소를 물리주소로 변환하는 작업을 담당하는 HW 블록입니다.
프로세서, OS, 소프트웨어가 사용하는 주소는 '가상주소'(Virtual Address)입니다. 반면에 실제로 메모리에 접근하기 위해서는 '물리주소'(Physical Address)가 필요하죠.
프로세서 및 소프트웨어가 메모리에 접근하기 위해 가상주소를 이용한 명령어를 호출하면, MMU 안에 있는 변환 테이블 (Translation Table) 룩업(look-up)과정을 거쳐서 맵핑되는 물리주소로 변환됩니다. TLB(Translation Lookaside Buffer)라는 주소 변환 테이블의 캐시같은 곳을 Table Walk Unit이 탐색하기 시작하면서 맵핑되는 물리주소를 찾습니다. 찾았다면, 이 물리주소로 메모리에 접근합니다.
12.2. 가상주소 vs 물리주소
세상에는 다양한 메모리 공급사가 있으며 서로 다른 물리 메모리 맵을 사용합니다. 즉, 물리 메모리 주소 공간의 각 공간을 어떻게 배치하는지 저마다 다르단 뜻입니다.
- 프로세스 입장에서 시스템이 어떤 메모리를 사용하는지 파악한 후 메모리별로 서로 다른 주소를 접근해야 한다면 정말 복잡할 것입니다. 소프트웨어 개발자 입장에서는 SoC에 어떤 메모리가 탑재돼있는지 매번 확인하고, 작성한 레거시 코드들을 다 하나하나 뜯어고쳐야 할겁니다.
- 프로세스와 메모리 사이에 가상주소라는 레이어를 끼워넣어봅시다.
- 이제 프로세스는 복잡한 경우를 생각하지 않고 자신만의 가상주소를 가지고 동작하면 됩니다. 가상주소에 접근하면, 이러쿵저러쿵 과정을 거쳐서 적절한 물리주소로 변환됩니다.
- 해당 물리주소로 메모리에 접근한 뒤 데이터를 가져옵니다.
VA를 사용해서 얻는 이득을 정리하면 다음과 같습니다.
- 여러 군데로 조각화된(Fragmented) 물리주소를 하나의 큰 연속된 덩어리로 간주할 수 있습니다.
- 각 프로세스는 오직 자신만의 독립된 메모리 덩어리를 가질 수 있습니다.
- 독립된 메모리 공간 덕분에 같은 PA를 서로 다른 VA로 가리킬 수 있습니다. 즉, 주소를 다루는 데 유연성이 크게 증가합니다.
이렇듯, 가상주소를 사용하면 시스템에 큰 이점을 가져올 수 있습니다.
12.3. (★) 주소 변환 과정
위에서 본 것 같이 가상주소를 사용하면 분명히 장점이 있지만, 주소를 변환하는 오버헤드가 발생하는 것 또한 사실입니다.
빠른 주소 변환을 위해 대표적으로 두 가지 방법을 사용하는데,
- TLB: 최근 변환한 VA-PA 정보를 기록해둡니다. 기록이 있다면 변환 필요없이 바로 기록 이용합니다.
- 다단계: 큰 범위에서 작은 범위로 좁혀가며 특정 물리 메모리 프레임을 특정합니다.

- 프로세서가 메모리에 접근하기 위해 가상주소를 사용합니다.
페이지 테이블 또는 TLB의 각 엔트리는 가상 페이지 번호와 해당 페이지가 매핑된 물리 메모리의 프레임 번호를 저장합니다. - MMU는 이 주소의 일부를
ⓐ TLB에서 특정 entry를 찾기위한 부분
ⓑ 나머지는 물리 메모리의 프레임 내에서 원하는 값을 찾기 위한 offset으로 이용합니다.

일반적으로 페이지 테이블은 캐시와 마찬가지로 보다 더 빠른 탐색 및 변환을 위해 다단계 계층구조로 구현돼있습니다. 캐시는 L1에서 없으면 L2에서 찾고, L2에 없으면 L3에서 찾았더라면, 페이지 테이블은 큰 범위에서 작은 범위로 탐색 범위를 좁혀가는 용도로 사용합니다.
싱글 페이지
- 만일 가상주소 1-page가 4KB인 시스템이 있다면, 페이지 테이블의 각 entry는 4KB일 것입니다.
- 32-bit 아키텍처라 가정해도 가리킬 수 있는 전체 주소 공간은 4GB입니다.
4KB로 쪼갰다면 테이블에는 100만 개가 넘는 entry가 있을 것입니다. - 메모리 접근 때마다 길이가 100만인 배열을 순차탐색해야한다고 생각해보세요. 성능에 치명적일 것입니다.

멀티레벨 페이지
- 이번에는 3단계 페이지 테이블을 도입해서, L1 페이지 테이블은 1GB단위로, L2는 256KB 단위로, L3는 4KB 페이지단위로 entry가 돼있다고 가정합시다.
- 먼저 큰부분 (e.g.1GB 블록단위)을 찾고, 중간부분 (e.g. 2MB 블록단위)를 찾고, 작은부분 (e.g. 4KB 블록단위)으로 특정 페이지(프레임)을 가리키는 엔트리를 찾습니다.
자연수 2453이 있을 때, 1부터 하나씩 늘리면 탐색하는하는 것보다,
1000단위-100단위-10단위-1단위로 탐색하는게 훨씬 효과적이겠죠?

가상주소는 64-bit를 사용하지만 실질적으로 주소를 가리키는 데 사용하는 부분은 일부입니다. 그리고 그 일부를 위의 멀티레벨 페이지 테이블의 각 entry를 찾기 위해 정해진 bit로 나눠서 취급합니다. Level 3 방식은 39-bit를 주소로 사용하고, Level 4 방식에선 48-bit를 주소로 사용합니다. 가상주소의 몇 bit를 실제로 주소를 나타내는 부분으로 사용할 것인지는 TCR_EL1 레지스터의 T0SZ, T1SZ 필드로 제어할 수 있습니다.

- 먼저, 'TTBRn_EL1' 레지스터에서 Level 1 페이지 테이블의 시작주소를 얻습니다.
- 위 그림들을 보면, [38:30] 필드가 Level 1 페이지 테이블에서 사용하는 부분입니다. 시작주소에 더해 원하는 엔트리를 찾습니다. (수식으로 나타내면 (*TTBRn_EL1 + ([38:30] * 8-byte)))
- 해당 엔트리에는 다음 레벨 변환 테이블(Level 2 변환 테이블)의 시작주소가 들어있습니다.
- 과정 2에서 했던것과 똑같이, 이번에는 [29:21] bitfield를 이용해 Level 3 변환 테이블의 시작주소를 찾습니다.
- 마지막으로 [20:12] bitfield를 이용해 엔트리를 찾습니다. 여기에 페이지와 맵핑되는 물리주소 프레임 주소가 들어있습니다.
이 주소에 VA 속 offset 부분을 덧붙여주면, 우리가 정말 접근하고자 했던 물리주소를 얻게됩니다.
이쯤되니 한 가지 의문이 생기네요.
- '같은 물리주소를 서로 다른 가상주소가 가리켜도' 문제 없습니다. 각 프로세스가 독립된 가상주소 영역을 가지는 게 애초에 목적이었으며 TLB가 올바르게 변환해줄테니까요.
- 그렇다면 '같은 가상주소인데 서로 다른 물리주소를 가리킨다면' 어떻게 될까요?
- 프로세스 A는 물리주소 '사과'를, 프로세스 B는 물리주소 '수박'을 얻고자 VA 0x8000을 호출합니다.
- 서로 독립된 주소공간을 갖기 때문에 충분히 일어날 수 있는 상황입니다.


'TTBRn_ELx' 레지스터에는 테이블 시작주소 뿐만 아니라 현재 실행중인 프로세스에 대한 ASID(Address Space ID)도 기록됩니다.
원래는 각 프로세스마다 독립된 가상주소 공간을 사용하기 때문에, 앞서 말씀드린 주소 충돌이 발생할 수 있어서 context switching을 할 때는 TLB를 비우는 flush 작업을 해야 맞습니다. 그러나, ASID 덕분에 TLB를 flush 하지 않고 일부 entry를 재활용할 수 있습니다.
Index ASID PA_Base Attributes
[0]: Process_A 0x8000 RW
[1]: Process_B 0x8000 RW
[2]: Process_B 0x8100 RW
[3]: Process_A 0x8100 RW- TLB에 위와같이 entry가 4개 있다고 가정합시다.
- [0]과 [1] 그리고 [2]와 [3]이 같은 물리주소 `0x8000`, `0x8100`을 가리키지만 ASID가 다르므로 구분할 수 있습니다.
- Process A를 실행하다가 Process B로 context switching이 발생합니다.
- TLB를 flush를 하지 않더라도 우리는 Process B ASID를 가지고 있는 [1], [2]번 인덱스의 entry를 재활용할 수 있습니다.
- [0], [3]은 ASID가 다르기 때문에 무시합니다.

애플리케이션이 동작하는 익셉션레벨 0, 유저영역과 커널이 동작하는 익셉션레벨 1, 커널영역이 구별돼있습니다.
가상주소는 MSB(63번 bit)가 0인지 1인지에 따라 어느 영역을 가리키는지 구별되는데,
`0x000...`으로 시작하는 주소는 사용자 공간에서 사용하는 가상주소고,
`0xFFF...`으로 시작하는 주소는 커널 영역에서 사용하는 가상주소입니다.
이번 포스트의 내용을 정리하면

위와 같은 순서대로 메모리에 접근합니다.
'Embedded' 카테고리의 다른 글
| 【공부/정리】 시스템 소프트웨어 개발을 위한 ARM 아키텍처 구조와 원리 ③ GIC, 트러스트존, 하이퍼바이저 (0) | 2025.03.01 |
|---|---|
| 【공부/정리】 시스템 소프트웨어 개발을 위한 ARM 아키텍처 구조와 원리 ② 익셉션과 익셉션레벨 (0) | 2025.02.28 |
| 【공부/정리】 시스템 소프트웨어 개발을 위한 ARM 아키텍처 구조와 원리 ① 레지스터와 명령어 (0) | 2025.02.26 |
| Aarch64 Memory Management 요약 정리 (0) | 2025.02.25 |
| [정리/요약] ARM Cortex-M 프로그래밍 (0) | 2025.02.11 |