1. Kernel 용어에 대해
1.1. OS의 등장
OS 등장배경을 간단하게 요약하면 다음과 같습니다.
- 당시 개발자는 프로그램 자체 기능뿐만 아니라 프로그램이 온전하게 메모리에 올라가기 위해 필요한 일련의 복잡하고 까다로운 작업을 컴파일 단계부터 시작해서 스스로 해야만 했습니다.
- 시간이 지나 대부분 프로그램들에 공통점이 있다는 점을 알게됩니다. 모든 SW는 키보드로 입력받고 모니터에 출력하는 등 I/O를 수행한다는 공통점이 있었습니다.
- 메모리에 I/O 기능을 포함한 SW를 자동으로 로드하고 실행해 모니터에 출력하는 환경을 구축한 것이 OS의 시초입니다.
즉, 태초의 OS는 DOS형태로 실행만 해주면 자동으로 메모리에 올려 실행하고 I/O를 가능하게 만들어주는 형태였습니다.
1.2. Kernel vs OS
정확하게 경계를 정의할 수 없고 모호해 둘을 구분짓기 어려워 용어 관련해서 논쟁이 많습니다.
Kernel은 리눅스 (링크) 같은 모놀로틱 커널과 L4 (링크) 같은 마이크로 커널로 나뉩니다.
- 둘 다 커널을 자칭하고 있지만, 각자 '커널'이 의미하는 바가 조금 다릅니다.
- 마이크로에서는: 시스템이 동작하는데 필수적으로 필요한 진짜 중요한 핵심 코어 부분을 담당하는 SW를 커널이라고 부릅니다.
- 모놀로틱에서는: 핵심 코어 부분에 네트워크, 장치관리 같은 다른 여러 큰 부분까지 합쳐서 OS나 다름없는 상태의 SW를 커널이라고 부릅니다. 여기서는 커널 = OS = 리눅스 인 셈이죠.
공통적으로 커널은 시스템 동작에 필수적인 코어 (e.g. 프로세스 스케줄링, context switching, 메모리 및 자원관리, ISR 지원 등)를 말합니다.
중요한 것은 커널이 막 혼자 숨쉬고 돌아다니며 전체 시스템을 관리하는 신비한 존재가 아니라는 사실입니다.
결국 커널이 알고있는 (사전 정의된) API를 호출하 요청이 들어올 때 정의된 동작을 수행하는 SW입니다.
이런 맥락에서 RTOS == embedded OS == Kernel이라고 정의해도 괜찮을 것 같습니다.
2. Task
2.1. Task란?
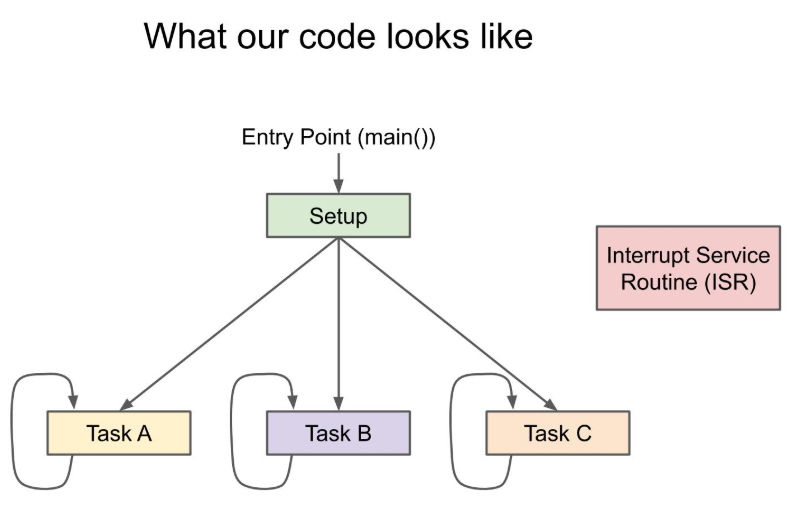
Embedded SW는 기본적으로 무한 loop 구조를 가집니다. 시스템 전원이 꺼질 때까지 무한히 정해진 일을 반복하는 것입니다.
- Task는 하나의 작업 맡아서 무한 loop 구조로 반복하는 함수/ 스레드/ 프로세스입니다.
- Task scheduler는 각 task 사이의 순서를 관리하고 다음번에 실행될 task를 결정한 뒤 context switching을 일으킵니다. 따라서 task는 scheduling(=context switching)의 기본(최소) 단위입니다.
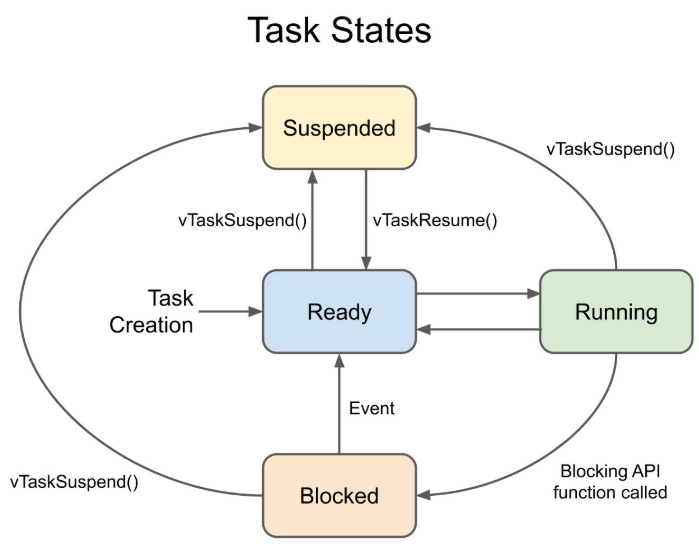
Task는 init/ wait/ ready/ running 4가지 상태를 가집니다.
- Init: Task가 생성된 뒤 무한 loop를 돌기 전에 필요한 준비물(e.g. 지역변수 등)을 준비하는 단계입니다.
- Wait(Blocked/ Suspended): Task가 특정 signal을 기다리는 상태입니다. 자신의 순번을 반환하고 signal이 올 때까지 기다리고 scheduler는 다음 차례 task를 선택하고 수행합니다.
- Ready: 기다리던 signal을 받았습니다. Task는 다시 수행될 준비를 마치고 scheduler에게 다시 선택받기를 원한다고 알리고 기다립니다. Signal을 받았다고 바로 실행되는 게 아니고 이렇게 'Ready' 상태로 존재합니다.
- Running: scheduler에게 선택받은 task가 CPU time을 점유해 실행되는 상태입니다.
2.2. 스케줄링 : 선점과 비선점
멀티태스킹(Multitasking)이란, 하나의 CPU에서 2개 이상의 작업을 동시에 처리/실행하는 것을 말합니다. 하지만 동시성을 구현하는 것은 까다롭기 때문에 보통 시분할 방식을 사용해서 '마치 동시에 수행하는 것처럼' 보이도록 눈속임을 합니다. Task A를 0.1초, Task B를 0.1초, Task C를 0.1초 이런식으로 각 task마다 CPU time을 나눠서 가진다면, 사람이 보기에는 마치 동시에 여러 task가 수행되고 있는 것처럼 보이는 꼴입니다.
이때, 구현방식에 따라 생각할거리가 몇 가지 생깁니다.
- 각 task가 CPU time을 나눠서 가지는 순서는 어떻게 정해야 할까요?
- 모든 task가 CPU time을 똑같이 나눠가져야 할까요?
- 지금 어떤 task를 수행 중인데, 당장 처리해야 하는 급한 task가 생기면 어떻게 할까요?
이런 고민들에 어떻게 대답하냐에 따라
- Preemptive(선점형): Task 마다 '우선순위'를 가지고있고, 상대적으로 우선순위가 높은 task가 발생한다면 실행 중이던 우선순위가 낮은 task로부터 CPU 제어권을 빼앗아 선점할 수 있도록 처리합니다.
- Non-preemptive(비선점형): Task 마다 일정한 간격으로 CPU time을 나눠가집니다.
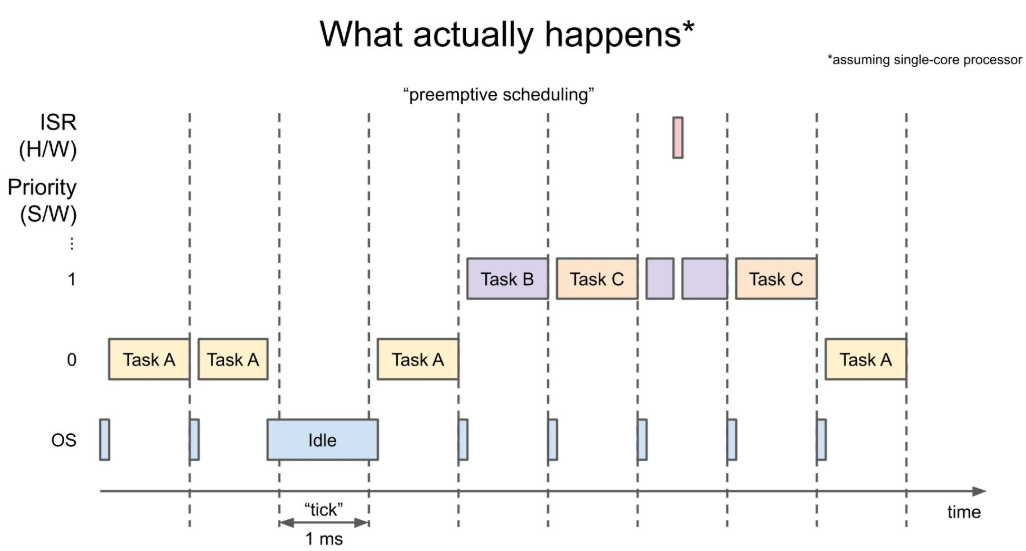
Priority 기반의 preemptive 스케줄러는 위 그림과 같이 우선순위가 높은 Task가 발생했을 때
- 현재 진행중이던 task를 멈추고 Wait 상태로 바꾼 뒤 요청받은 우선순위 높은 task를 먼저 처리하도록 스케줄링합니다.
- Task A를 처리하고 난 뒤 Task B 요청을 받아 Task B가 수행되고,
- Task B를 수행하다 인터럽트가 걸려 중간에 ISR을 먼저 처리하는 것을 볼 수 있습니다.
- 심지어는 ISR을 수행하는 도중에도 더 높은 우선순위의 인터럽트가 걸리면, 해당 인터럽트를 처리하기 위한 ISR이 선점합니다. 이에 대해서는 조금 뒤에 더 자세하게 다루겠습니다.
3. Context switching과 TCB
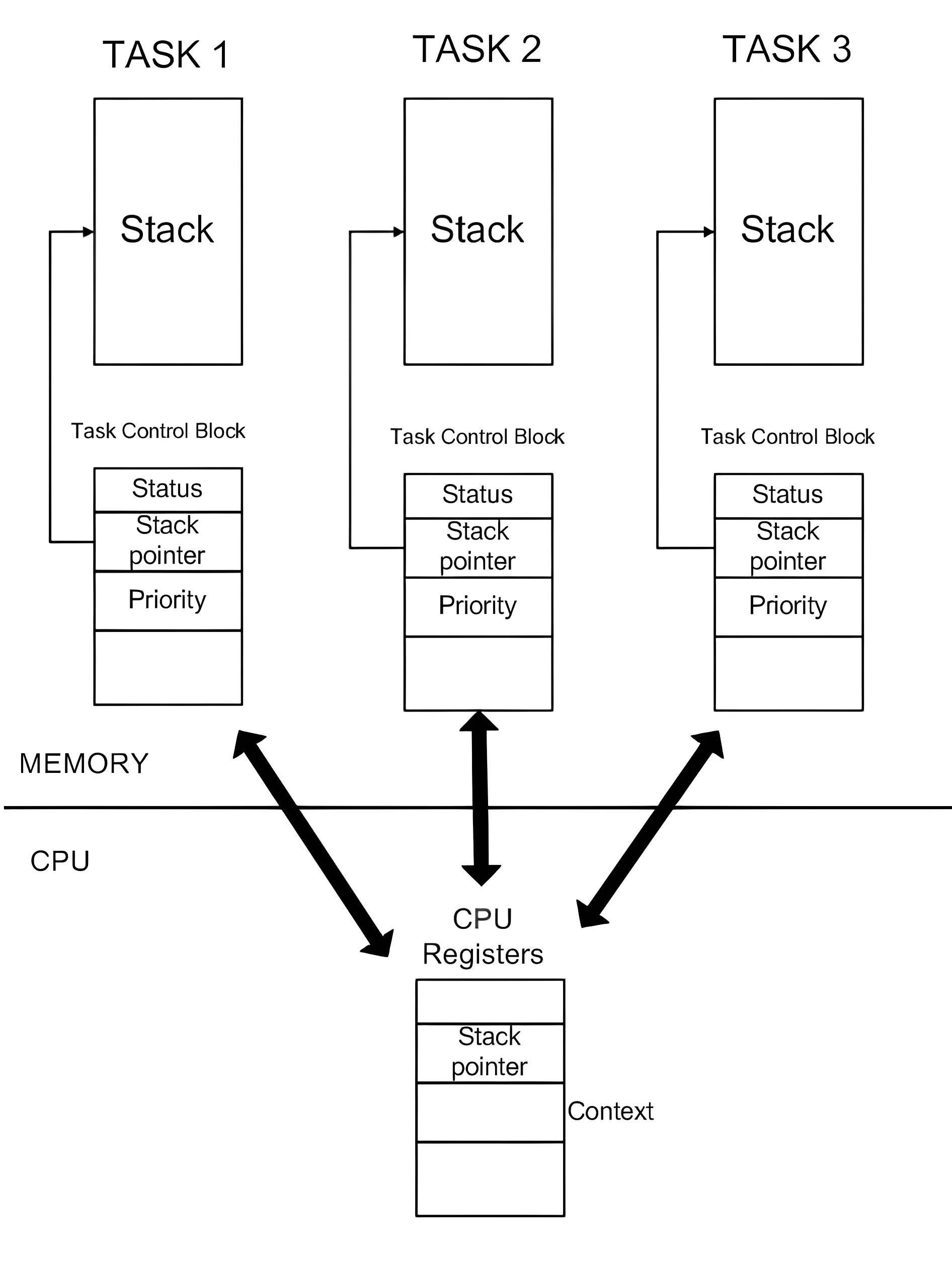
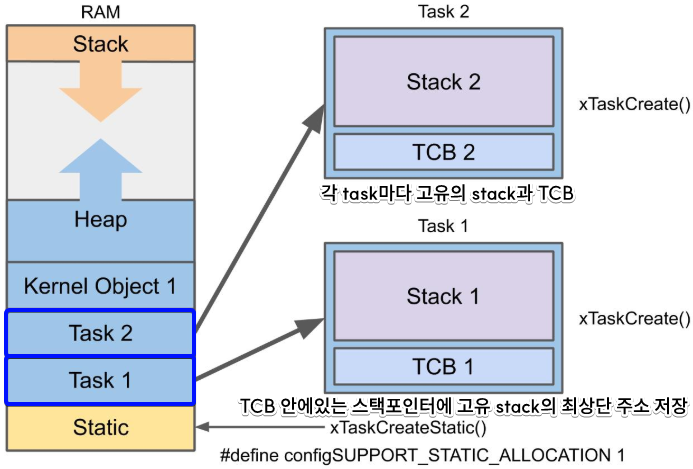
모든 Task는 저마다 자신만의 스택과 TCB (Task Control Block)을 가집니다.
TCB는 context switching에 필요한 정보들을 저장하는 자료구조입니다. 대표적으로 task의 이름, task만의 스택포인터, 현재 기다리고 있는 signal 정보, 우선순위 등이 저장됩니다. 스케줄러는 이 TCB로 현재 해당 task가 이전에 어디까지 진행했는지 정보를 얻습니다.
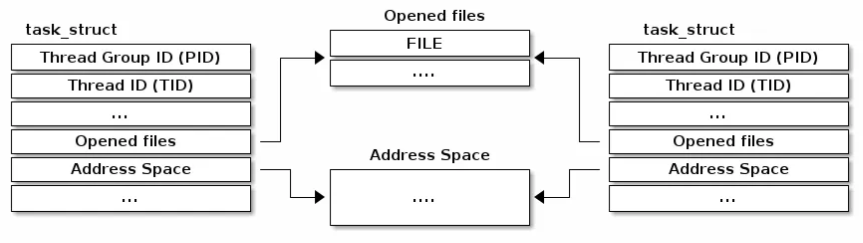
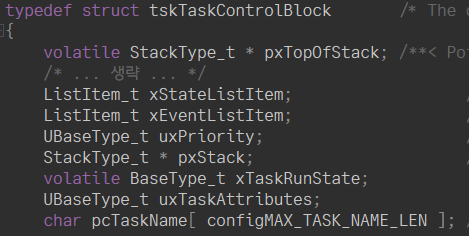
실제로 TCB는 위와 같은 구조체 연결리스트 형태로, task에 대한 정보가 들어있습니다.
( Linux Kernel의 task_struct 구조체, FreeRTOS의 tskTaskControlBlock 구조체 )
스케줄러의 역할은 크게 두 가지입니다.
- 다음번에 실행될 task를 결정합니다.
- Context switching을 수행합니다.
(CPSR 저장/복구, TCB의 스택포인터가 가리키는 주소에 context 저장, TCB 스택포인터 갱신, 추후 context 복구)
; 현재 task의 context를 백업하는 과정
STMFD SP!, {LR} ; LR을 stack에 저장한다.
SUB SP, SP, #4 ; R13은 TCB에 따로 저장할거니까 비워두기
STMFD {R0-R12} ; R0~R12를 stack에 저장한다.
MRS LR, CPSR ; LR은 이미 저장했으니 CPSR 저장하는 temp 저장소로 사용
STMFD SP!, {LR} ; CPSR을 stack에 저장한다.
LDR R0, =CUR_TASK_TCB ; 현재 task의 TCB 시작주소 가져와서
STR SP, [R0, #TCB_SP_POS] ; 방금 비워뒀던 TCB의 스택포인터에 TCB 시작주소 넣어준다.
; 다음 task의 context를 복구하는 과정
LDR R0, =NXT_TASK_TCB
LDR SP, [R0, #TCB_SP_POS] ; 다음 task TCB의 스택포인터 가져온다.
LDMIA SP!, {R0} ; CPSR의 F랑 C 자리 가져와서 SPSR에 저장한다.
MSR SPSR_F, R0
MSR SPSR_C, R0
LDMIA SP!, {R0-R12, LR, PC}^ ; R0~R12랑 PC값 갱신한다. LR은 그냥 쓰레기값.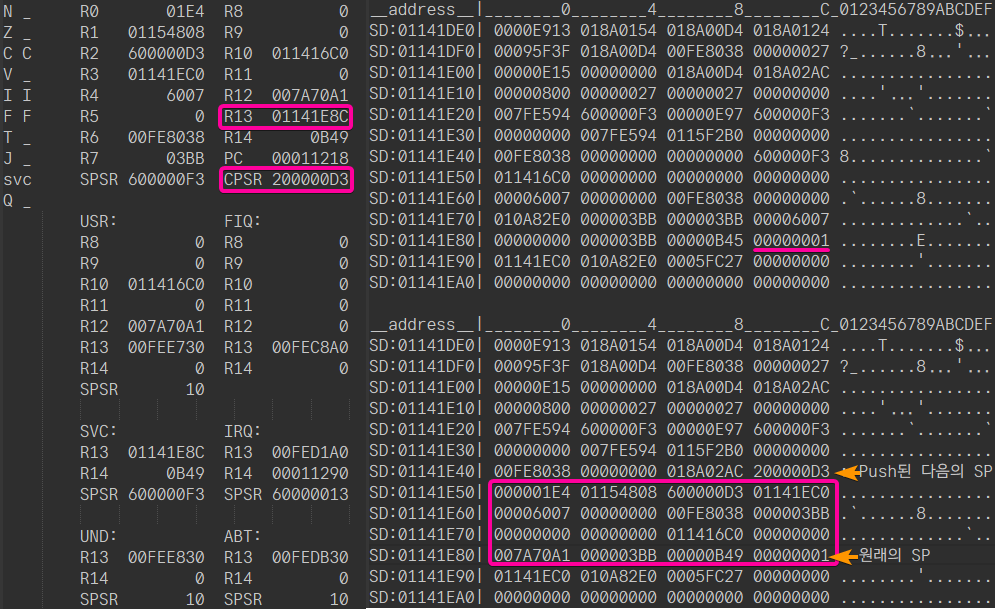
- R13을 먼저 확인해 봅시다. `0x0114_1E8C`네요. 메모리를 덤프해보니 `0x0000_0001`을 가리키고 있습니다.
- 이 지점으로부터 현재 task의 context를 저장합니다. LR, R12~R0, CPSR 순으로 저장합니다. (그래서 저 사각형 친 영역의 R13 (`0x0000_03BB`)은 쓰레기값입니다.)
- 새롭게 갱신된 스택포인터 `0x0114_1E4C`를 현재 TCB의 스택포인터를 저장하는 필드에 저장합니다.
4. ISR (Interrupt Service Routain)
4.1. ISR 적용하기
Task와 task 사이의 스케줄링에 대해서 배웠으니 이번에는 Task보다 우선순위가 높은 인터럽트의 스케줄링에 집중해 보겠습니다.
1. 인터럽트가 발생하면 IRQ exception이 걸립니다.
2. Exception vector table로 jump -> IRQ handler로 jump 합니다.
3. 원래 실행하던 task로 복귀합니다. 이때 미리 복귀주소 LR <- PC - 4로 보정해야 하는 거 기억하시죠?
간략하게나마 코드로 구현하면 다음과 같습니다.
SUB LR, LR, #4
STMFD SP!, {R0-R12, R14}
.....원하는 ISR 특정.....
LDR R3, =TARGET_ISR
BLX R3
LDMFD SP!, {R0-R12, R14}^
(`^` 기호 쓰임새 저번 chapter에서 배웠던 거 기억하시죠? SPSR->CPSR 됩니다.)
위 코드를 보면, '원하는 ISR 특정'하는 부분이 있죠? 당연히 시스템에 인터럽트가 1개만 있을 리가 없습니다. SoC의 Interrupt Controller는 peripheral로부터 인터럽트가 걸렸을 때, 프로세스에게 n번 인터럽트가 걸렸음을 알려주는 역할을 합니다. IRQ mode 진입 후 프로세서는 interrupt controller 관련 레지스터들을 읽어서 몇 번 인터럽트가 걸렸는지 식별할 수 있습니다.
// Interrupt controller 레지스터가 `0x8000_0000`번지에 있다고 가정
void __irq IRQ_Handler() {
uint32 IRQ_NUM;
uint32* which_irq = 0x80000000;
IRQ_NUM = *which_irq; // n번 인터럽트 특정
ISRVector [IRQ_NUM](); // n번 IRQ Handler 호출
}
먼저 `__irq` 지시자 (gcc에서는 `__attribute__((interrupt( irq )))`)를 이용해서 함수를 IRQ handler로 만들 수 있습니다. 컴파일러는 이런 지시자가 붙은 함수를 만나면 자동으로 바로 위에서 봤던 어셈블리 (context 넣고, 다시 복원해 주는 코드)를 넣어줍니다.
4.2. Bottom half (DPC + APC)
ISR은 되도록 짧고 간결하게 작성하는 것이 원칙입니다. 일반적으로 ISR은 모든 task보다 우선순위가 높기 때문에 다른 task들이 계속 기다리고 있어야 하기 때문입니다. 이러한 기아(Starvation) 현상을 방지하기 위해서 보통 bottom half 방법을 사용합니다.
Linux kernel에서도 사용하는 bottom half 기법은 DPC (Deferred ISR, Deferred Procedure Call), APC (Asynchronous Procedure Call)라고도 부릅니다. 핵심은 ISR은 정말 급한 것만 빠르게 처리하고, 나머지 작업은 따로 task를 만들어서 처리하도록 만드는 것입니다. 그리고 이렇게 따로 만든 DPC task가 다른 task들한테 밀리지 않도록 우선순위는 상대적으로 꽤 높게 설정해야 하고, 실행하는 도중에 인터럽트가 걸리지 않도록 막는 것도 좋습니다.
DPC는 어떻게 만들까요?
- ISR을 끝내기 직전에 DPC task를 생성한 후 나갑니다.
- 또는 미리 DPC 전용 Queue를 만들어놓은 뒤, ISR을 끝내기 직전에 enqueue 하고 Queue를 관리하는 task에 signal을 보낸 뒤 나갑니다.
4.3. Nested Interrupt
ISR을 실행하는 도중에도 더 높은 우선순위의 인터럽트가 걸리면 해당 ISR이 선점하게 됩니다. 이를 중첩 (Nested) ISR이라고 합니다.
중첩 ISR 처리과정은 간략하게 표현하면 다음과 같습니다.
- 기본적으로 어떤 인터럽트에 대한 ISR이 수행될 때는 그보다 낮은 우선순위의 인터럽트는 비활성화합니다.
- 더 높은 우선순위 인터럽트가 걸리면 counter 변수를 하나 증가시키고 선점당합니다.
- 다시 돌아올 때는 counter 변수를 감소시킨 뒤 원래 처리하던 ISR로 돌아와서 이어서 진행합니다.
- ISR이 종료될 때 counter 변수가 0이라면 더는 처리할 인터럽트가 없기 때문에 원래 실행하던 task로 돌아가거나 현재 ready 상태인 task들 중에 가장 우선순위가 높은 task로 돌아갑니다.
4.4. Clock Tick ISR (Timer)
Tick ISR 또는 Timer는 이름대로 정해진 시간마다 주기적으로 인터럽트를 발생하는 서비스를 말합니다. 주로 정해진 시간 후에 어떤 일을 수행하고 싶거나, 일정 주기마다 어떤 일을 반복하고 싶을 때 사용합니다.
- Clock Tick ISR API를 이용해서 callback 함수와 시간을 등록합니다.
- Clock Tick ISR들이 저장된 queue를 순회하며 시간을 감소시킵니다.
- Clock Tick ISR은 정해진 시간마다 한 번씩 인터럽트를 발생시킵니다.
+ Watchdog
Watchdog timer란, 모든 task가 정상적으로 운용되고 있음을 확인해 문제 발생 시(i.e. starvation, deadlock 등) HW적으로 타깃을 reset 시키는 HW timer입니다.
Watchdog timer를 관리하는 task는 다른 모든 task의 실행주기를 파악하고 있습니다.
- 모든 task는 주기마다 한 번씩 이 task에게 ‘저 정상적으로 잘 동작했어요’라고 보고해야만 합니다.
- 이 관리자 task는 주기적으로 wake-up 돼 task들이 잘 보고했는지 확인한 뒤 문제 확인 시 시스템을 reset 시킵니다.
Watchdog에 의해 시스템이 리셋됐을 때, 범인은 보고를 하지 않은 task일 수도 있지만 보통 그보다 우선순위가 높은 task가 원인인 경우가 많습니다. 걔 때문에 다른 task가 starvation에 처했을 가능성이 높기 때문입니다.
5. Idle task
5.1. Kernel 진입점
지난 챕터에서 `__main` 진입점, `__rt_entry()` 함수 그리고 `main()` 함수가 호출되는 과정을 배웠습니다.
Kernel 은 이 중에서 언제 실행되는 SW일까요? 바로 `main()` 함수입니다.
void idle_task(void) {
define_tasks(); // task들을 정의하고 생성한다.
start_tasks(); // task들을 실행하고 scheduler도 실행한다.
while (1) {
wait_signal(IDLE_SIGNAL);
}
}
void kernel_init(
tcb_type pTcb,
byte* pStack,
dword priority,
func_type fTask,
char* pTaskName) {
pTcb->sp = pStack; // SP 초기화
pTcb->priority = priority; // 우선순위는 최하위로!
while ( (pTcb->task_name[idx] = pTaskName[idx]) && (idx++ < 200));
fTask(); // idle task를 실행한다.
}
int main(void) {
kernel_init(
&idle_task_tcb,
(void *)idle_stack,
idle_priority,
idle_task,
"IDLE_TASK"
);
return 0;
}
- Kernel에서 가장 먼저 하는 일은 task가 동작하지 않는 동안 돌아갈 task인 'idle task'를 생성하는 겁니다.
- Idle task는 그 어떤 task도 실행되지 않을 때 kernel을 점유하고 있는 task입니다.
- 다른 task에 영향을 주지 않도록 우선순위는 최하위로 설정됩니다.
- Idle task는 kernel API를 통해서 다른 task들을 시작하는 역할도 합니다. 따라서 task들을 정의하는 부분 (`define_tasks()`)과 시작하는 부분(`start_tasks()`)이 idle task에 들어가 있습니다.
- 스케줄러는 이제 kernel 및 idle task 위에서 정의된 task들을 우선순위에 따라 스케줄링합니다.
- 모든 task가 wait state 또는 sleep 상태일 때 IDLE_SIGNAL signal이 전달돼 idle task가 깨어나고, 다른 task들 중 어느 하나라도 깨어날 때까지 계속 무한루프를 돕니다.
이때, 어떤 task도 실행되지 않을 때 idle task가 돌아가도록 놔두기보다는 타깃 프로세서에서 지원하는 여러 sleep mode를 활용하는 것이 전력소모면에서 좋습니다.
5.2. Kernel 포팅이란?
'커널을 포팅한다'는 말을 자주 들어보셨을 텐데, 이게 정확히 무슨 의미일까요?
포팅(Porting)한다는 것은 '이미 만들어져 있는 SW가 다른 target에서 정상적으로 동작할 수 있도록 수정 또는 개선하는 작업을 총칭'하는 것입니다. 그러므로, 필연적으로 어떤 CPU 종속적인 코드를 다른 CPU 종속적인 코드로 변환/수정하는 작업이 포함됩니다.
- Context switching 과정 및 백업/복원해야 하는 context에 대한 고려
- 스택 구현 방법에 대한 고려
- 인터럽트를 활성/비활성하는 방법과 처리하는 방법에 대한 고려
- Watchdog timer 설정에 대한 고려
등 거의 모든 CPU마다 달라질 수 있는 사항을 고려하고 수정해야 합니다. 이는 커널뿐만 아니라 타깃 프로세서의 동작원리와 동작방식을 모두 이해해야 가능하기 때문에 매우 어려운 작업입니다.
'Embedded' 카테고리의 다른 글
| 임베디드 레시피 Chapter 8. Debug (0) | 2025.02.01 |
|---|---|
| 임베디드 레시피 Chapter 7. Device control (0) | 2025.02.01 |
| 임베디드 레시피 Chapter 5. SW ② 스택 (0) | 2025.01.29 |
| 임베디드 레시피 Chapter 4. ARM ② Assembly와 Bootloader (1) | 2025.01.29 |
| 임베디드 레시피 Chapter 3. SW ① 컴파일부터 로드 (0) | 2025.01.25 |