
Chapter 1. 개요
임베디드 시스템의 아키텍처는 MCU를 중심으로 주변장치(peripheral) 및 외부 세계와 통신하기 위한 특별한 인터페이스 모음입니다.
임베디드 SW의 핵심은 peripheral과의 통신입니다. 단순히 프로그래밍을 넘어 기초 전자공학지식, 회로도와 datasheet를 이해하는 능력, 로직 분석기 및 오실로스코프 같은 측정도구 활용능력을 이용해서 peripheral과의 안정적인 통신을 구현합니다.
제한된 자원
임베디드 SW 개발에는 자원이 제한 돼있기 때문에, 잘 정의된 테스트 케이스 & 성능 지표 탄탄한 workflow 기반의 개발이 필요합니다.
- MCU에는 MMU(Memory Management Unit, 물리주소→ 가상주소 변환 등 주소 관리해주는 핵심요소)가 없을 가능성이 높습니다.
- 일부 경우, 프로세서는 (MMU가 없으니) 주소 변환 없이 flash에서 직접 instruction을 순차적으로 가져와 바이너리를 실행할 수도 있습니다. 이를 XIP (eXecute In Place) 라고 합니다.
- 부족한 메모리를 보완하기 위한 보조수단입니다.
- 상황들
- 새로운 기능을 구현하기 위한 충분한 용량의 메모리나 Flash가 없을 수 있습니다.
- 프로세서가 데이터를 처리하기에 충분히 빠르지 않을 수 있습니다.
- 요구사항을 만족하기 위해 더 적은 전력을 소모해야 할 수도 있습니다.
- 메모리는 항상 부족하기 때문에 모든 연산에 잠재적으로 필요한 메모리 양 및 버퍼를 항상 고려해야 합니다.
- OS가 없는 경우가 대부분이므로 memory swapping, relocation 등 고급 OS 기능에 기대할 수 없습니다.
ARM Cortex-M 제품 특징
- 16개의 범용 Register가 있습니다.
- 코드 밀도 최적화를 위한 16bit용 Thumb Instruction format을 제공해 코드 밀도 최적화를 달성합니다.
- 8~16개의 우선순위를 지원하는 NVIC (Nested Vector Interrupted Controller) 덕분에 낮은 우선순위의 인터럽트를 처리하던 도중 더 높은 우선순위의 인터럽트가 걸려고 문제없이 높은 우선순위의 인터럽트를 처리하고 복귀할 수 있습니다.
- 선택적 8구역 MPU (Memory Protect Unit)
- 선택적 TEE isolation 메커니즘 (ARM TrustZone-M)
- ARMv6-M (M0, M0+), ARMv7-M (M3, M4, M7),, ARMv8-M (M23, M33) 아키텍처
- 32-bit 아키텍처이므로 전체 메모리 주소공간은 4GB로 할당돼있으며 내부 RAM의 시작은 일반적으로 고정된 주소 `0x2000_0000`에 매핑돼있습니다. 플래시에 대한 매핑은 제조업체에 다릅니다.
Chapter 2. 작업환경과 워크플로 최적화
다른 애플리케이션 개발과 마찬가지로, 작성한 소스파일을 기계가 이해할 수 있는 언어로 변환하고 메모리에 올려주는 역할을 해줄 도구들이 필요합니다. 임베디드 환경에서는 여기서 한 단계가 추가되는데, 호스트(개발하는 쪽) 환경과 타겟(프로그램이 돌아가는 쪽) 환경이 다르다는 점입니다. 따라서 프로그래머는 특정 머신, 특정 타겟을 위한 컴파일 및 디버깅을 해야 하는데, 이런 도구모음을 툴체인 (toolchain)이라 합니다. ARM이 제공하는 임베디드 툴체인 중 대표적으로 'arm-none-eabi'가 있습니다.
툴체인은 일반적으로 다음과 같이 구성돼있습니다.
- 컴파일러: GNU/리눅스 배포판의 GCC가 대표적이며 `.c` 소스코드를 `.o` 오브젝트 파일로 만듭니다. 호스트와 타겟이 다를 때는 크로스 컴파일러라고 부르며 이때 하는 컴파일은 크로스 컴파일이라 부릅니다.
- 링커: 오브젝트 파일들의 심볼 의존성을 모두 처리해 실행파일로 만드는 역할을 합니다. ELF 포맷을 따르는 실행파일이 만들어지며, 프로그램을 실행하기 위해 필요한 다양한 정보가 섹션별로 정리돼 기록돼있습니다.
- `.text`: 프로그램 코드가 저장되는 공간, 읽기 전용입니다.
- `.rodata`: 런타임에 수정되지 않는 `const` 상수가 저장되는 공간, 읽기 전용입니다.
- `.data`: 초기화 된 또는 초깃값을 갖고 있는 변수들이 저장되는 공간입니다.
- `.bss`: 초깃화되지 않은 또는 초깃값을 갖고 있지 않는 변수들이 저장되는 공간힙니다. `main()` 함수 실행 이전에 이 영역에 있는 값들은 모두 `0`으로 초기화 됩니다.
- 링커스크립트: 타겟의 메모리 섹션과 각 섹션의 시작점, 종점 등 자세한 설명이 기록된 파일입니다. 링커가 바이너리를 메모리로 올리기 위해 필요한 정보를 제공함과 동시에 이렇게 로드해주세요 라고 규칙도 제공하는 일종의 레시피입니다.
- 빌드 자동화 툴: 소스파일을 만들면 최종 바이너리 이미지 생성까지 자동으로 만들어주는 표준 도구로, GNU의 Make라던지, 오픈소스의 CMake 등이 대표적입니다. 사용자가 직접 레시피나 규칙을 적용해 입맛에 맞는 출력 파일을 자동으로 생성해줄 수 있는 강력한 도구입니다.
- 디버거: 디버거는 CPU register와 memory의 현재 상태를 직접 살펴보면서 런타임 속 오류를 잡아낼 수 있도록 돕습니다.
- 이때, 임베디드 SW 개발환경은 타겟 환경과 다르기 때문에 디버깅도 호스트에서 하지않고 원격으로 합니다.
- JTAG 또는 SWD 인터페이스를 통해 타겟에 접근하고, 일부 개발보드는 USB를 통해서도 연결할 수 있도록 변환 칩이 내장돼있습니다.
- 타겟 JTAG/SWD에 접근할 수 있도록 해주는 오픈소스 도구로는 openOCD (On-Chip Debugger)가 있습니다.
QEMU
Host PC에서 전체 타겟 플랫폼을 `qemu`로 에뮬레이션하면 위험성을 줄이고 이식성 요구 없이 타겟머신에 특화된 코드를 실행하고 디버깅할 수 있습니다. `qemu`가 ARM의 HW와 특수기능을 상당히 정확하게 구현하고 있지만, 실제 HW와 시스템 레이아웃과 완전 일치하지 않는 경우가 있기 때문에 한계는 분명히 있습니다. 그렇지만, 기능을 숙지하는 데 가장 좋습니다.
Chapter 3. 개발 및 설계 패턴과 작업방식
개발의 효율을 높이기 위해 협동 및 동기화를 최적화합니다.
- 리비전 제어 - Git을 이용한 버전 관리
- 이슈 추적 - 알려진 시스템의 버그와 활동을 계속 추적
- 코드 리뷰
- 지속 통합 - 주기적으로 또는 코드 변경 시에 자동으로 동작을 수행하고, 테스트 결과를 수집하고, 동료 개발자 통지를 통해 빌드 및 테스트 실행 작업 등을 스케줄링합니다.
3.1. 하드웨어 추상화
타겟 MCU의 종류는 굉장히 다양하고, 그 설계와 세부 구성이 모두 다르므로 하드웨어를 추상화해야만 개발자가 펌웨어를 개발하기 편해지고 재사용 가능한 코드를 작성할 수 있습니다.
ARM은 CMSIS (Cortex Microcontroller Software Interface Standard)라는 레퍼런스 표준을 만들어 하드웨어를 성공적으로 추상화했습니다. 서로 다른 하드웨어를 제어하기 위한 코드가 API 형태로 제공되므로 개발자는 API 내부의 복잡한 연산들에 대해 고려하지 않고도 CMSIS를 통해 서로 다른 두 하드웨어를 동일한 방법으로 개발할 수 있습니다.
3.2. 임베디드 프로젝트의 생애 주기
개요
현대 개발 프레임워크 (e.g. 애자일 개발 방법론 등)는 ① 작업을 더 작은 업무로 나누고, ② 마일스톤을 표기하고, ③ 중간 작업물을 생산하도록 권합니다. 이러한 추천사항은 임베디드 프로젝트에서는 특히 효율적이고 효과적입니다.
- 업무를 최소화하고 작은 업무를 하나씩 수행하는 것은 전체 시스템에 치명적일 수 있는 오류가 존재하는 환경에서 취약점과 리그레션을 신속히 식별하는 효율적인 방법입니다.
- 중간 마일스톤은 가능한 한 많이 자주 수립하는 것이 좋습니다.
- 개발 초기단계에서 가능한 한 최종 시스템의 프로토타입을 생성하는 것이 좋습니다.
- 이 과정에서 아래 사항들이 가능해집니다.
- 작업 우선순위 파악
- 개발 업무 간 의존성 파악
- 예상치 못한 이슈 파악
- 시스템의 동작과 HW의 한계에 대한 이해
- 설계 및 관점 수정
- 물론 설계 및 사양을 변경하는 것은 큰 작업을 필요로 합니다.
- 하지만, 프로젝트의 낡고 문제가 있는 부분을 버리고 새로 잘 설계된 것으로 교체할 경우 보통 품질 면으로 이득이 될 가능성이 높고 추후 생산성이 향상될 가능성도 높습니다. 이러한 리팩토링 프로세스를 오버헤드라 생각하기 보다는 시스템 향상의 과정이라 생각합시다.
- 이 과정에서 아래 사항들이 가능해집니다.
단계
1단계: 프로젝트 정의 단계
- 사양을 분석하고, 요구사항을 정의하고, 우선순위를 할당하며 결과물이 이뤄야 할 기능을 정의합니다.
- PM10 센서로 매 시간 측정 값을 내부 플래시에 저장하고, 하루에 한 번 무선통신으로 게이트웨이로 통계를 전송하는 공기 품질 모니터 기기를 설계한다고 가정합시다.
- 최종 목적을 이루기 위해 수행될 단계의 목록 (순서는 다를 수 있지만)은 다음과 같습니다.
- 1) 타깃에 최소 시스템 부트, 2) 로그 기록을 위한 포트 0 직렬통신 연결 설정, 3) 센서와 통신을 위한 포트 1 설정, 4) 타이머 설정, 5) PM10 센서 드라이버 제작, 6) 매 시간 센서로부터 통계값을 읽는 웹/앱 애플리케이션 제작, 7) 통계값 저장/복구를 위한 flash 하위 모듈 제작, 8) 무선통신 드라이버 제작, 9) 게이트웨이와 통신하기 위한 프로토콜 구현
2단계: 프로토타입 제작 단계
- 위에서 정의한 기능들 중 핵심적인 일부 기능 (e.g. 시스템 부트, 포트 설정, 타이머 설정, 센서 드라이버)을 구현합니다.
- 무선통신처럼 '당장' 무언가를 할 수 없는 기능의 경우에는 동작 확인만 가능한 정도로 (e.g. 원시패킷 전송) 구현합니다.
3단계: 리팩토링 및 고도화 단계
4단계: API 및 문서화 단계
- API는 시스템과 애플리케이션 사이의 계약입니다.
- 개발 전에 설계돼야 하고, 개발자가 최종 작업물로 향해 나아가는 중에 가능한 한 변경이 적어야 합니다.
- 주석을 달며 문서화를 할 때 주의해야 할 점은, 좋은 심볼 이름과 짧고 간단하게 유지된 함수는 때로 주석이 필요하지 않을 정도로 구체적으로 API의 기능을 충분히 설명해준다는 점입니다.
- 또한, 코드에 대해 가치있는 부가설명을 제공하지 못하는 주석을 추가하는 것은 되려 코드 가독성을 떨어트리는 원인이 됩니다.
Chapter 4. Boot-up Processs
4.1. IVT (Interrupt Vector Table)
- IVT는 인터럽트를 처리하기 위한 handler 함수인 ISR (Intrrupt Service Routain)들의 시작주소를 모아둔 함수 포인터 배열입니다.
- IVT는 보통 바이너리 이미지의 시작 부분에 있고, Flash의 가장 낮은 시작주소에 저장됩니다.
- ARM Cortex-M은 메모리 최상위 16자리에 시스템 인터럽트를 정의해놨는데 종류는 다음과 같습니다.
- Reset
- NMI (Non-Maskable Interrupt)
- Hard fault
- Memory exception
- Bus fault
- Usage fault
- Supervisor call (Scheduler)
- Debug monitor (Breakpoint)
- PendSV (Shared resources, Semaphore)
- System Tick (Timer)
4.2. Start-up 코드
링커스크립트의 `.text` 섹션 가장 첫 부분에는 IVT에 대한 부분이 들어가야 합니다.
.text : {
*(.isr_vector),
*(.text*),
*(.rodata*)
} > FLASH // Flash에 할당되는 읽기전용 내용들시스템이 부트업 하기 위해서는 가장 먼저 IVT를 읽고, reset handler 함수가 실행돼야 하기 때문입니다. 그래야 `.bss`, `.data` 섹션에 정의된 심볼들이 초기화 됩니다.
4.2.1. IVT 정의하기
IVT의 주소를 1단계에서 기재했으니, 2단계에서는 IVT 내부에 각 예외마다 필요한 ISR의 포인터를 연결해줘야 합니다. GCC의 attribute인 `section`을 사용합니다.
__attribute__ ((section(".isr_vector")))
void (* const IV[])(void) {
(void (*)(void))(END_STACK), // Stack pointer 초기값 지정
isr_reset,
isr_nmi,
...
}
// ISR은 parameter도 return도 없다.
void isr_reset(void) {
/*...구현...*/
while(1) {}
}
// 사용자 정의 ISR 또는 빈 ISR은 오버라이드 될 수 있도록 __weak 심볼을 사용한다.
void isr_user(void)__weak {
/*...구현...*/
while(1) {}
}4.2.2. Reset Handler에 대한 설명
MCU에 전원이 들어오면, IVT 최상단에 정의된 reset handler `isr_reset`가 가장 먼저 실행됩니다.
- Reset handler는 `.data`와 `.bss` 섹션을 초기화합니다.
- 우선 flash 속 `.data` 섹션을 메모리로 복사해서 옮깁니다. 초깃값이 있기 때문에 수정이 필요하기 때문이죠.
- 초깃값이 없는 `.bss`섹션은 모두 0으로 초기화 해버립니다.
void isr_reset(void) {
unsigned int *src, *dst;
// .data 섹션 시작주소~끝주소까지 복사.
src = (unsigned int *) &_stored_data;
dst = (unsigned int *) &_start_data;
while (dst != (unsigned int *) &_end_data) {
*dst = *src;
dst++;
src++;
}
// .bss 섹션 시작주소~끝주소까지 0으로 초기화.
dst = &_start_bss;
while (dst != (unsigned int *) &_end_bss) {
*dst = 0;
dst++;
}
main(); // main() 함수 호출
}4.2.3. `.data`, `.bss` 섹션 초기화하기
링커스크립트는 스크립트 내에서 물리주소(LMA, Load(또는 Logical) Memory Address) 와 가상주소(VMA, Virtual Memory Address)를 분리하는 메커니즘을 제공합니다. 메모리에 올라갔을 때 할당받는 가상주소는 런타임에야 결정되기 때문에 컴파일타임에는 알 수가 없습니다. 따라서, 물리주소 ≠ 가상주소임을 알릴 수 있도록 `AT` 키워드를, '지금 이 주소는 결정되지 않지만, 나중에 결정될거야'를 알릴 수 있는 `.` 키워드를 사용해서 `.data`, `.bss` 섹션을 아래와 같이 올바르게 구현할 수 있습니다.
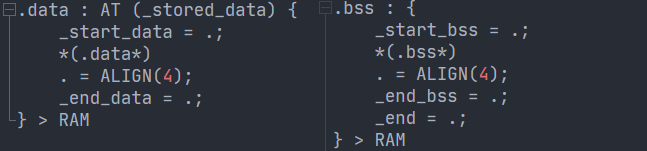
- `data`는 `AT` 키워드를 이용해서 물리주소가 flash의 `_stored_data`임을 알리고, 가상주소는 `_start_data`에서 시작함을 명시합니다. 이때, 값이 `.`이므로 현재 이 값은 알 수 없지만, 나중에 자동으로 처리됨을 알립니다.
- `.bss` 섹션 역시 마찬가지입니다. 초깃값을 갖고있지 않으므로, 물리주소를 따로 지정할 필요가 없습니다. `.bss` 영역의 크기 정보만 알면 메모리에서 해당 크기만큼만 할당해준 뒤 `0`으로 초기화 해버리면 그만일테니까요. 따라서 `AT` 키워드를 사용할 필요없이 `_start_bss`만 `.으로 선언합니다.
4.2.4. 스택 할당
위 1, 2단계에서 간략하게나마 부팅 후 링크스크립트에 기재된 내용대로 메모리 레이아웃 속 주소들이 결정되는 것을 확인할 수 있었습니다. 메모리를 사용하는 스택도 마찬가지입니다. 링킹 후 링크스크립트의 `END_STACK` 심볼에는 메모리의 사용하지 않는 영역 중 가장 끝, 마지막 주소를 담고있습니다. 이렇게 계산된 `END_STACK`, 스택의 끝 주소는 상수여야 하고, IVT 시작부분에 기록됩니다.
4.3. 메모리 레이아웃 및 4.2절 정리
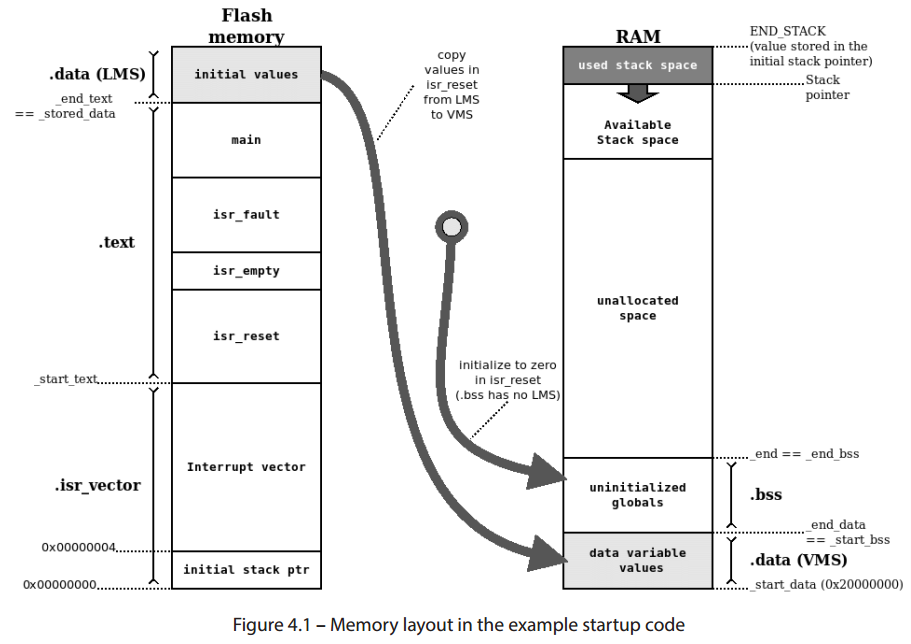
위 4.2 절에서 배운 내용을 정리하면 위 그림과 같습니다.
- IVT가 Flash에 있는 것, `.isr_vector`로 정의된 것을 확인하세요.
- Flash에 `.text`와 `.data` 섹션이 있는것을 확인하세요.
- `.data` 섹션은 읽기 및 수정을 위해 메모리에 올라와야하므로 복사되기 위해 화살표 표시 된 것도 확인하세요.
- `.bss` 섹션은 물리메모리를 갖지 않는것을 확인하세요. 섹션 영역크기만 잡히면 메모리에서 그 영역(`_start_bss` ~ `_end_bss`)을 `0`으로 초기화합니다.
- 메모리에서 사용하지 않는 영역 중 최상단(제일 끝)이 `END_STACK`으로 할당되고, 여기서부터 스택이 할당되는것도 확인하세요.
실행 바이너리가 링크될 때, 링크스크립트에 정의된 심볼들은 메모리 내 각 섹션의 시작과 끝을 가리키도록 컴파일타임에 자동 결정됩니다. 또, 각 섹션의 크기 역시 컴파일타임에 알 수 있습니다. (이 정보들은 컴파일 이후 산출물인 '.map' 파일을 읽으면 확인할 수 있습니다.)
4.4. 빌드 및 실행
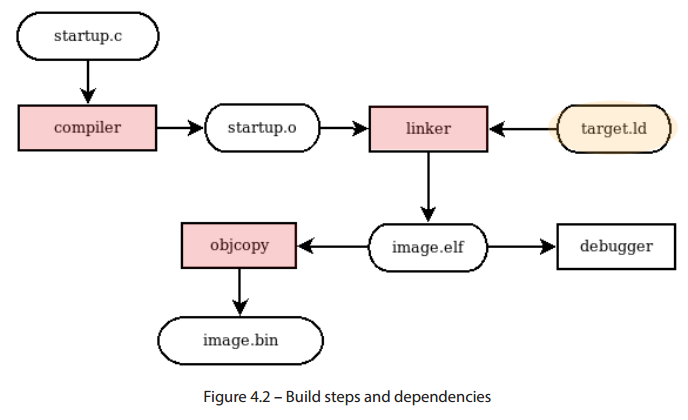
- 소스파일은 오브젝트 파일로 컴파일 및 어셈블됩니다.
- 링커는 링커스크립트 `.ld`파일에서 제공되는 정보를 이용해 올바른 섹션에 심볼을 초기화합니다.
- objcopy는 ELF 파일을 실행 바이너리로 변환해주는 역할을 합니다.
일련의 과정을 수행하는 Make 빌드 코드는 다음과 같습니다.
CROSS_COMPILE=arm-none-eabi-
CC=$(CROSS_COMPILE)gcc
LD=$(CROSS_COMPILE)ld
OBJCOPY=$(CROSS_COMPILE)objcopy
CFLAGS=-mcpu=cortex-m3 -mthumb -g -ggdb -Wall -Wno-main
LDFLAGS=-T target.ld -gc-sections -nostdlib -Map=image.map
image.bin: image.elf
$(OBJCOPY) -O binary $^ $@
image.elf: startup.o target.ld
$(LD) $(LDFLAGS) startup.o -o $@
$(CC) -c -o $@ $^ $(CFLAGS)- 변수 `$@`와 `$^`는 각각 타깃 ( `:` 기준 좌측, 결과물, 산출물)과 의존성 목록( `:` 기준 우측)으로 치환됩니다.
- `-nostdlib` 옵션은 기본 C 라이브러리를 자동으로 링크하지 않음을 보장합니다.
4.5. 부트로더 및 멀티부트
우리가 사용하는 데스크탑, 노트북 뿐만 아니라 MCU 같은 작은 임베디드 머신에도 부트로더가 들어갈 수 있고, 심지어 유용합니다.
- 기존 버전의 임베디드 SW가 시스템 위에서 동작하고 있는 상태에서 새로운 기능과 버그를 수정한 새로운 버전을 원격에서 업데이트를 할 수 있는 수단을 제공합니다.
- 부트 전에 현재 실행할 애플리케이션 이미지의 무결성을 검증할 수 있습니다. 만일 손상됐다면 장애 극복 메커니즘을 도입할 수도 있습니다.
부트로더는 하나의 독립된 애플리케이션으로 취급되며 분리된 코드를 실행합니다.
- 따라서 타겟 입장에서 본다면 한 번에 (하나의 이미지에) 두 개의 애플리케이션이 메모리에 올라오는 것과 같고
- Flash 입장에서 본다면, IVT가 2개, `.text`, `.data` 섹션도 2개로 마치 데스크톱에서 파티션을 나눈것과 같게됩니다.
- `0xE000_ED08` 번지에 위치한 VTOR (Vector Table Offset Register) 레지스터는 복수개의 IVT 중 어느 IVT를 사용할 것인지를 런타임에 결정할 수 있도록 돕는 역할을 합니다.
- 다만, M3부터 있기 때문에 M0, M0+는 불가피하게 Flash의 다른 영역에 별개의 함수포인터 배열을 정의해둡니다. 예외가 걸리면 이쪽으로 온 뒤, 현재 애플리케이션이 실행 중인지 아닌지 판단합니다. 애플리케이션이 실행 중이라면, 애플리케이션의 IVT의 ISR이 실행되고, 아니라면 부트로더의 IVT의 ISR이 실행됩니다.
- 부트로더가 자기 할 일을 모두 마치고 나면, 애플리케이션이 실행돼야겠죠? 그러기 위해서 애플리케이션의 IVT의 reset handler ISR로 직접 점프합니다. 이 과정은 reset handler 마지막에 `main()`을 호출하는 것과 거의 똑같습니다.
Chapter 5. 메모리 관리
MMU가 없는 대부분의 임베디드 시스템에서는 물리주소와 가상주소를 맵핑할 수 있는 수단이 없습니다.
따라서 (우리에겐 너무 당연했던) OS의 가상주소 관련 기능들을 사용할 수 없습니다.
- 각 프로세스가 고유한 가상메모리 공간을 가진다던지
- 시스템에 의해 현재 사용중인 메모리 블록의 크기와 위치가 변한다던지
- 가상 메모리 풀로부터 동적 메모리 할당을 받는다던지
이전 챕터에서 잠깐 다뤘지만, 링커스크립트를 통해 사전 정의된 섹션과 컴파일타임에 결정된 심볼 및 물리주소를 이용하게 됩니다. 이번 장에서는 ① 섹션을 적절히 구성하기 위해 알면 좋은 각 섹션의 다양한 특징들과 ② 메모리 영역을 관리하는 메커니즘을 배웁니다.
5.1. 메모리 모델과 주소공간
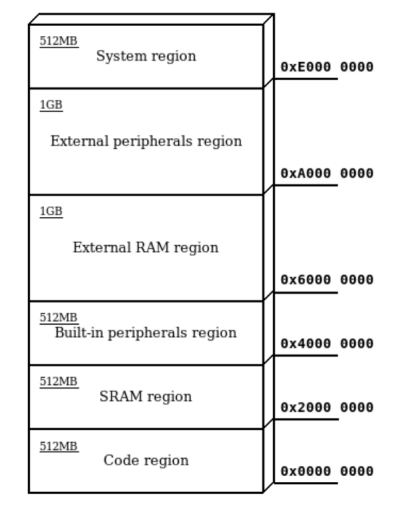
ARM Cortex-M 32-bits 머신은 연속된 4GB 메모리 공간을 참조할 수 있고 위와 같이 6개의 큰 구역으로 나뉘어 구성돼있습니다.
- Code rigion: 하위 512MB, 플래시 메모리를 매핑하는 런타임에 수정할 수 없는 읽기전용 영역입니다. XIP에 사용되거나 플래시의 `.text`, `.rodata`, `.data`가 여기로 옮겨집니다. `.data`는 수정 가능한 세그먼트로 복제 및 재매핑됩니다.
- RAM region: 내부 메모리는 `0x2000_0000`을 시작으로, 외부 메모리는 `0xA000_0000`을 시작주소로 합니다.
- Peripherals region: 내장된 주변장치 또는 외부 주변장치를 위해 예약된 공간으로, 이 구역에서의 코드 실행은 절대 허용되지 않습니다.
- System region: 최상위 512MB, 시스템 환경설정 및 프라이빗 제어 블록에 접근하기 위해 예약된 공간으로 시스템 제어 레지스터가 여기 할당돼있습니다. 접근하기 위해서는 프로세서가 높은 권한으로 실행중일 때만 가능합니다. 코드 실행은 역시 허용되지 않습니다.
메모리 트랜잭션 순서
분기예측, 자원휙득을 위한 대기 등 여러 최적화 메커니즘 때문에 instruction을 생성한 순서 그대로 실행되는것을 보장받기 어렵습니다. 이를 보장하는 특수한 메모리 베리어를 제공하는데, Cortex-M 기준 데이터 메모리 베리어 (DMB), 데이터 동기화 베리어 (DSB), 명령어 동기화 베리어 (ISB)를 제공합니다.
일반적으로 베리어를 사용하는 대표적인 상황은 (멀티 부트 환경에서) IVT 주소를 변경하기 위해 VTOR 레지스터를 갱신했을 때가 있습니다.
5.2. 실행 스택
스택은 높은 주소에서 낮은 주소로 (위에서 아랫방향으로) 자랍니다.
- 함수 호출마다 PSB(Program Status Block) 등을 백업/저장.
- 함수를 실행하는 동안 로컬 변수를 저장.
- 임시저장소로 사용.
임베디드 프로그래밍은 코딩 중 항상 자신이 얼마나 스택을 사용하고 있는지를 인식해야 합니다. 큰 객체를 사용하거나 재귀함수를 사용하는 것을 지양해야 합니다.
- 스택의 종점 주소(`_stack_end`)는 스택포인터가 가질 수 있는 주소의 상한을 의미합니다.
- 스택포인터는 `0`번지부터 시작해서 `_stack_end` 주소까지 낮은 주소를 향해 나아갑니다.
재차 설명드리지만, 스택은 위에서 아래로, 낮은 주소를 향해 자라납니다. - 스택 오버플로우를 막기 위한 최선의 전략은 ① 부트 시 적절한 스택 공간을 할당할 것, ② 런타임에 수시로 스택 사용량을 점검할 것, ③스택 페인팅이 있습니다.
- 사용 가능한 메모리 영역 중 `.bss` 섹션의 마지막 주소로부터 스택 종점 `_stack_end` 까지는 힙이 사용할 수 있는 영역입니다.
스택 페인팅
asm volatile("mrs %0, msp" : "=r"(paint));
dst = ((unsigned int *)(&_end_stack)) - (8192 / sizeof(unsigned int));
while (dst < paint) {
*dst = 0xDEADCODE;
dst++;
}스택 페인팅 (Stack painting) 이란, 사용가능한 메모리 영역에서 스택이 사용할 수 있는 공간에 페인트칠을 하는 겁니다. 리셋 핸들러를 이용하며, 예를들어, `static unsigned int paint;` 라는 전역정적 변수를 선언했다고 가정하면,
- `mrs %0, msp` 어셈블리로 현재 (초기화 완료 된) 스택포인터 값을 변수 `paint`에 저장합니다.
- 그리고 스택의 경계값 (`_end_stack`)으로부터 이 `paint` 까지 올라가면서 (반복하지만 스택은 낮은 방향으로 자라니 경계값이 더 낮은 주소에 있을겁니다) `0xDEADCODE`로 페인트칠 합니다.
이를 런타임에 주기적으로 실행합니다. 그러면 애플리케이션이 실행하다가 가장 많은 스택을 사용했을 때를 파악할 수 있습니다.
이 방법으로 애플리케이션을 안정적으로 수행하기 위해 필요한 최소, 최선의 스택공간의 양을 검증할 수 있습니다.
5.3. 힙(Heap) 관리
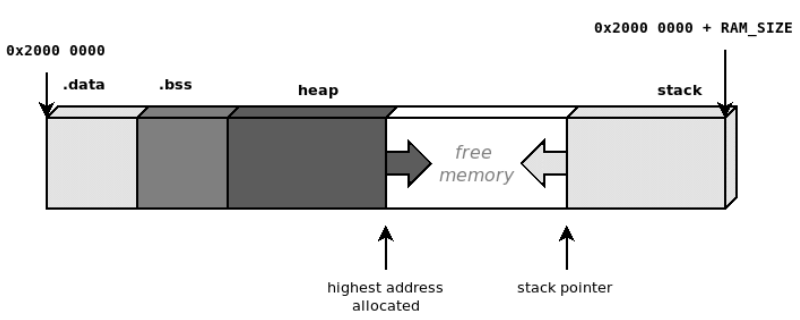
`.bss` 섹션의 마지막 주소로부터 스택 포인터까지는 사용 가능한, 확장 가능한 메모리 영역입니다.
스택은 아래로 향하면서, 힙은 위로 향하면서 확장하므로 언제나 충돌가능성이 존재하게 됩니다.
이 때문에 안전이 중요한 임베디드 시스템은 일반적으로 어떠한 동적 메모리 할당도 하지 않도록 막습니다.
하지만, 동적 메모리 할당은 강력하고 편리한 도구입니다. 메모리의 할당 상태와 크기에 대한 추적, 다음 요청에 대응하기 위해 여유 메모리 파악, 해제한 블록을 나중에 재사용할 수 있도록 하는 등 메모리 블록의 생애를 완벽하게 관리해줍니다. 그래서 다양한 서드파티에서 동적 메모리 관리 및 힙 관리자를 구현한 라이브러리를 유료 또는 오픈소스로 내놓고 있습니다.
일반적으로 단일 목적 임베디드 시스템은 동적 메모리 할당을 피하도록 권장합니다.
힙 메모리 및 힙 관리자를 도입한다면,
- 스택의 하위 경계를 정하듯, 충돌을 막기 위해 힙도 적절한 상위 경계를 설정해야 합니다.
- 요청을 만족할만큼 충분한 여유 메모리가 없을 경우에 대응해야 합니다.
- 메모리 단편화를 최소화하고 적절하게 처리해야 합니다.
- 물론, 단편화는 완전하게 해결할 수 없습니다.
- 빈번한 `malloc() / free()` 호출을 피하고
- 최대 메모리 할당 크기/개수를 통제 범위 내에 두고,
- 가능한 한 많은 블록을 재활용할 수 있도록 해야 합니다.
- 더 안전한 코드를 작성합니다.
- 할당받은 메모리는 사용전에 한 번 더 검증(`NULL`이 반환됐는지 아닌지)해야 합니다.
- 이미 해제된 메모리를 다시 해제하려는건 아닌지 검증해야 합니다.
- 객체의 생애를 철저히 분석하고, 객체를 사용하는 부분은 최대한 깔끔하고 쉽게 로직을 만듭니다.
ARM-GCC 임베디드 툴체인에는 동적 메모리 할당 메커니즘을 제공하는 'newlib' 라이브러리를 제공합니다. newlib 라이브러리는 시스템콜 구현을 제공하므로 타겟이 단일 스레드 베어메탈 애플리케이션이든, 복잡한 RTOS든 모두 사용할 수 있도록 합니다.
5.4. 메모리 보호 유닛 (MPU)
MMU가 없어서 가상주소 맵핑이 없는 시스템에서는 런타임에 자신이 접근하는 메모리 주소가 어느 섹션인지 명확한 구분이 어렵습니다. 링커스크립트에서 구획/섹션을 나눴던것처럼 MPU는 메모리상 섹션에 로컬 권한과 속성을 부여해 명확한 구분을 도와주는 기능입니다. 대표적인 사용 시나리오 예시는 다음과 같습니다.
- 특정 메모리 영역을 사용자모드일 때는 접근하지 못하도록 막는 경우
- 쓰기/실행이 가능한 메모리 영역에서 특정 코드를 실행할 때, 영역이 오염되는 것을 막기 위해 이 영역에 대한 명령어 인출(fetch)을 막는 경우
- 스택영역과 힙영역 사이에 격벽을 만들어 충돌을 방지하는 경우
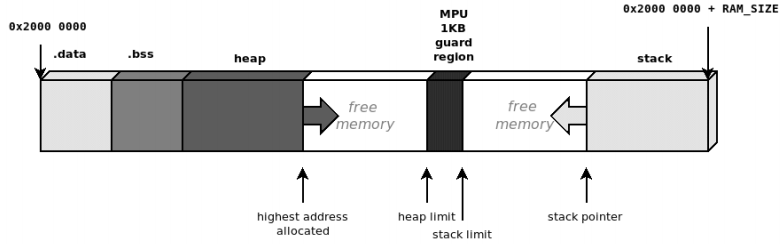
start = (uint32_t)(&_end_stack) - (STACK_SIZE + 1024); // Stack 종점으로부터 + 1KB
attr = RASR_ENABLED | MPUSIZE_1K | RASR_SCB | RASR_NOACCESS | RASR_NOEXEC;
// Enable MPU + Region size 1KB + Region controlled by SCB + NO R/W/E
mpu_set_region(2, start, attr);- 스택 종점으로부터 1KB 떨어진 위치로부터 읽기/쓰기/실행 모두 불가능한 보호영역(guard region)을 만듭니다.
- 위 그림과 같이 격벽이 만들어져 힙 영역과 스택 영역이 물리적으로 분리돼 스택오버플로우를 방지합니다.
Chapter 6. 주변장치
6.1. NVIC
인터럽트는 시스템이 구동되는 내내 언제나 발생할 수 있습니다. 심지어는 한 인터럽트를 처리하는 동안에도 말이죠. 따라서, 인터럽트에 각기 다른 우선순위를 부여하고, 우선순위가 높은 인터럽트는 선점을, 우선순위가 낮은 인터럽트는 지연함으로써 시스템이 우선순위가 높은 인터럽트에 더 빠르게 반응할 수 있도록 합니다.
NVIC (Nested Vector Interrupt Controller) 덕분에 우선순위 부여, 우선순위 그룹화, 런타임 중 우선순위 변경 등이 가능합니다.
#define NVIC_ISER_BASE (0xE000E100) // SET
static inline void nvic_irq_enable(uint8_t n) {
int i = n / 32;
volatile uint32_t *nvic_iser =
((volatile uint32_t *)(NVIC_ISER_BASE + 4 * i));
*nvic_iser |= (1 << (n % 32));
}
#define NVIC_ICER_BASE (0xE000E180) // CLEAR
static inline void nvic_irq_disable(uint8_t n) {
int i = n / 32;
volatile uint32_t *nvic_icer =
((volatile uint32_t *)(NVIC_ICER_BASE + 4 * i));
*nvic_icer |= (1 << (n % 32));
}
#define NVIC_IPRI_BASE (0xE000E400)
static inline void nvic_irq_setprio(uint8_t n, uint8_t prio) {
volatile uint8_t *nvic_ipri =
((volatile uint8_t *)(NVIC_IPRI_BASE + n));
*nvic_ipri = prio;
}고정된 주소에 NVIC 설정 관련 레지스터가 있고, 위와 같이 설정합니다. 레지스터의 각 bit는 사전에 정의된 특정 인터럽트와 대응돼있어 활성화하거나 비활성화하거나 우선순위를 설정할 수 있습니다.
6.2. System clock
Cortex-M MCU의 Clock 환경설정은 RCC(Reset and Clock Control) 레지스터를 통해 가능합니다. 이때 MCU 제조사마다 내부에서 사용하는 PLL(Phase-Locked Loop) 로직이 조금씩 다르기 때문에 클럭을 설정할 때는 반드시 datasheet를 읽고 예제코드를 참고하는 것이 바람직합니다.
RCC 레지스터로 clock을 올바르게 설정했다면 ‘Peripheral Clock Source Register’의 대응하는 bit를 설정해서 주변장치를 위한 clock을 활성화할 수 있습니다. 만일 사용하지 않는 주변장치가 있다면, 여기서 clock을 끊어버린다면, 전력소모에 도움이 됩니다.
또, 인터럽트와 타이머 (또는 tick)는 땔래야 땔 수 없는 관계지요? MCU는 정기적으로 인터럽트를 걸 수 있도록 tick 인터럽트를 설정할 수 있습니다. Clock 소스로 무엇을 사용할지, 어느 주기로 인터럽트를 발생시킬지 등등을 입맛에 맞게 정의할 수 있다는 뜻입니다. 이때 사용하는 주 시스템 타이머를 'SysTick'이라고 합니다. 설령 SysTick이 없는 저가 MCU라고 할지라도 타이머 기능을 제공할 수 있도록 최소한 일반적인 타이머를 설정할 수 있는 수단들을 제공합니다.
안정된 CPU clock을 설정했다면, SysTick 타이머에 대한 환경설정을 진행합니다. RVR(Reload Value Register) 레지스터를 사용하면 프로세서의 clock을 2의 배수인 n으로 나눈 주파수를 SysTick에 설정할 수 있습니다.
마지막으로, 타이머 내부에는 시스템 클럭에 맞춰서 계속해서 증가하는 전역/정적인 타이머 변수가 있습니다. 코드 내에서 딱히 사용되지도 않고 겉보기에는 쓸모없이 선언된 변수처럼 보이기 때문에 컴파일러가 최적화 과정에서 생략하고 날려버릴 수 있으므로, 이를 방지하기 위해 반드시 타이머 변수들은 `volatile` 선언해야 합니다.
6.3. GPIO
MCU의 GPIO는 몇 가지 그룹(A, B, C, D …)으로 나뉘고 각 그룹과 관련한 입출력, 풀 업/다운 레지스터 등이 존재합니다. 이러한 레지스터들의 각 bit를 자유자재로 바꿔가면서 내부 (또는 외부) 주변장치와 통신합니다.
- GPIO 그룹을 위한 clock source을 활성화 합니다.
- GPIO 핀에 대해 입출력 모드를 결정합니다.
- GPIO 핀에 대해 풀업/풀다운 여부를 결정합니다.
- GPIO 핀에 대해 set/reset bit를 설정해서 값을 출력하거나 입력받습니다.
GPIO 핀에는 외부 인터럽트를 인지할 수 있는 컨트롤러가 연결돼있습니다.
- 덕분에 계속해서 GPIO핀을 읽으면서 '신호가 들어왔나?', '이번엔 들어왔나?' 하면서 폴링하지 않고
- 다른 일을 하다가 GPIO 핀으로부터 신호가 발생했을 때 인터럽트가 걸리도록 설정할 수 있습니다.
- GPIO 핀 인터럽트 활성화/비활성화부터 상승엣지에서 받을건지 하강엣지에서 받을건지, 단발성인지 한 번 인터럽트 걸리면 끝내는 단발성인건지 아니면 초기화하고 계속해서 대기할건지 등등을 레지스터를 제어해서 설정할 수 있습니다.
6.4. Watchdog
워치독은 무한루프처럼 시스템이 블로킹 상태에 빠졌거나 통제불능 상태에 빠졌을 때 강제로 재부팅을 시켜버리는 타이머이자 안전장치입니다. 시스템은 계속해서 자신이 정상작동하고 살아있음을 워치독에 알리고, 그때마다 워치독 타이머는 초기화됩니다. 하지만, 시스템이 블로킹 상태에 빠지면 그럴 수 없겠죠? 워치독 타이머 변수가 상한에 도달하게 되면, 시스템에 무언가 문제가 생겼다고 판단하고 강제로 재부팅을 시켜버립니다. 워치독 역시 다른 타이머처럼 레지스터로 환경설정 합니다.
Chapter 7. 로컬 버스 인터페이스
| 프로토콜 | 와이어 수 | Clock | 동기화를 위한 전략 | 비트 순서 | 통신 모드 |
| UART | 2개 (RX / TX) | 비동기 | baud rate, 패리티 비트 | LSB | 1:1, 1:多 |
| SPI | 3개 (MOSI/ MISO/ CLK) | 동기 | 클럭 라인 따로 있음 | MSB/LSB | 1:1, 1:多 |
| I2C | 2개 (SDA/SCL) | 동기 | 클럭 라인 따로 있음 | MSB | 1:1, 1:多 |
| CAN | 2개 (CAN-Hi / CAN-Low) | 비동기 | 시작비트-끝 시퀀스 | MSB | 1:多 |
직렬통신 (또는 시리얼통신)은 수신측과 송신측이 서로 메시지를 잘 주고받고 이해하기 위해서 클럭이 동기화돼야 합니다.
- 받는 쪽이 준비가 안 됐는데 메시지를 던지면 메시지는 사라질 것이고,
- 주는 쪽이 준비가 안 됐다면, 받는 쪽은 항상 계속 대기하고 있어야 합니다.
- 동기화 방식은 두 가지로,
- '이 통신 주파수(Baud rate)를 사용할 거에요'라고 서로 합의하고 통신하거나 (Async, 비동기)
- 동기화를 위한 추가 라인을 사용해서 한쪽으로부터 클럭 주파수를 전달받아 공유하면서 통신합니다 (Sync, 동기)
만약 프로토콜이 반이중(half-duplex) 통신 방식이라면, 하나의 라인을 한 방향(수신/송신)으로만 사용해야하고, 전이중(full-duplex) 통신 방식이라면, 수신을 위한, 송신을 위한 라인을 따로따로 사용해야 합니다.
7.1. UART
UART는 양방향 FIFO 버퍼를 이용합니다.
- 데이터를 쓸 때는 UART_DR 레지스터에 무언가를 쓰고,
- 데이터를 읽을 때는 UART_SR 레지스터의 특정 bit를 읽고 데이터가 들어왔는지 확인한 후 UART_DR 레지스터를 읽습니다.
이때, UART_SR 레지스터를 계속 주기적으로 확인하는 폴링 방식과, 데이터가 들어왔을 때 인터럽트가 걸리는 인터럽트 방식으로 나뉩니다. 당연히 인터럽트 방식이 반응성이 더 좋습니다.
7.2. SPI
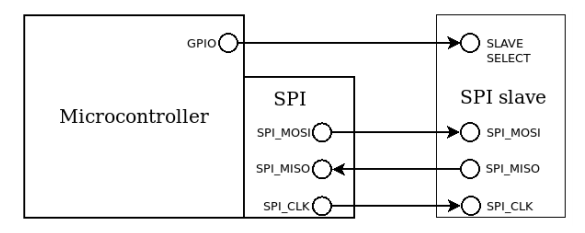
- Bus master의 clock 신호를 통한 동기화로 UART보다 빠르며 다수의 주변장치가 같은 버스를 공유할 수 있습니다.
- SPI 통신의 일련의 과정은 다음과 같습니다.
- Master는 SPI_CLK을 활성화합니다.
- Master는 SPI_MOSI에 명령어를 slave로 전송합니다.
- Slave는 SPI_MISO로 데이터를 master로 전송합니다.
- Slave로 전송할 데이터가 더 없더라도, clock을 유지하기 위해 master는 slave에게 dummy bytes를 SPI_MOSI로 계속 보냅니다. (이때, Slave는 이 dummy bytes를 무시합니다.)
예시
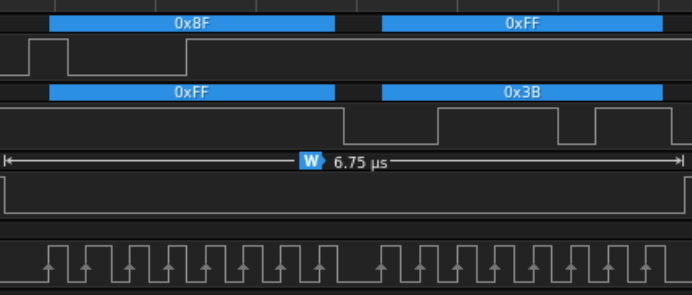
- Master는 `SPI_CLK`를 활성화 합니다.
- Master는 slave에게 `0x8F`라는 명령어를 `SPI_MISO`를 통해 보나기 시작합니다.
- 이 명령어는 slave(가속도계)의 데이터를 읽는 명령어입니다.
- Master가 slave로부터 처음에 SPI_MOSI로 받은 데이터 `0xFF`는 slave의 dummy bytes로 무시합니다.
- 명령을 받은 slave가 데이터를 준비하고, `SPI_MOSI`로 `0x3B`라는 데이터를 master에게 전송합니다.
- 이때 master는 더 이상 보낼 데이터가 없으므로 slave에게 0xFF라는 dummy bytes를 SPI_MISO로 보냅니다만, slave는 무시합니다.
SPI 역시 UART처럼 내부 FIFO buffer를 사용하고, busy waiting을 막기 위해 인터럽트 방식을 사용하는 것이 좋습니다.
7.3. I2C
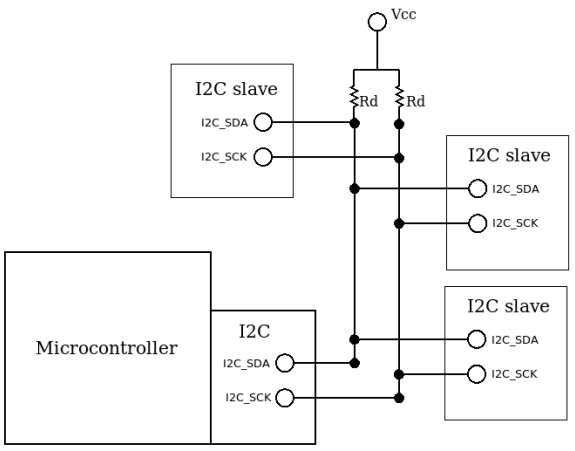
I2C는 전송속도가 느리지만, 저전력으로 통신이 가능한 프로토콜입니다. SPI와 공통점이 많지만, 고정 주소로 slave를 선택할 수 있기 때문에 I2C_SDA 핀 하나만으로 통신이 가능합니다.
- I2C_SCL: master와 slave 사이에 동기화된 통신을 진행.
- I2C_SDA: Address와 명령 그리고 데이터와 ACK/NACK 신호를 주고받음.
I2C 프로토콜 상세는 다음과 같습니다.
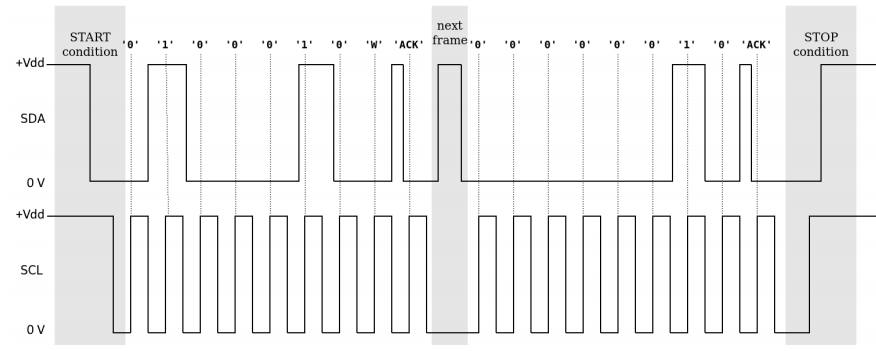
- Start 신호: I2C 시작을 알리는 특수 신호 조합입니다. `SCL = High, SDA = High → Low` 일 때 통신이 시작됩니다.
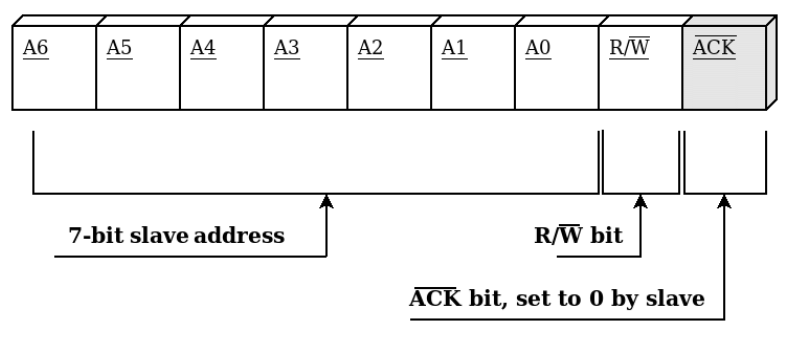
- 1st Frame - Address Frame
- 통신은 최소 두 가지 프레임으로 구성돼있습니다. 첫 frame은 주소를 전달하는 프레임입니다.
- 7-bit로 구성돼있는 Address 부분은 slave 하나를 특정하는 역할을 합니다.
- 끝에서 두 번째 bit는 이번 요청이 쓰기(`0`)인지 읽기(`1`)인지 구분해줍니다.
- 마지막 bit는 slave에 의해 결정되는 bit이며 `0`이면 ACK, `1`이면 NACK입니다.
- 2nd Frame - Data Frame
- 읽기 연산이라면, 첫 번째 프레임에 전달된 주소에 매칭되는 slave가 데이터를 master에게 보냅니다. Master는 잘 받았다는 신호 ACK를 slave에게 반환합니다.
- 쓰기 연산도 마찬가지로 첫 번째 프레임에 전달된 주소에 매칭되는 slave에게 데이터를 보냅니다. 마지막에 slave는 잘 받았다는 ACK 신호를 master에게 반환합니다.
- End 신호: 전송의 끝을 알리는 종료 조건입니다. `SCL = High, SDA가 Low → High`로 바뀌면 I2C 통신의 종료를 의미합니다.
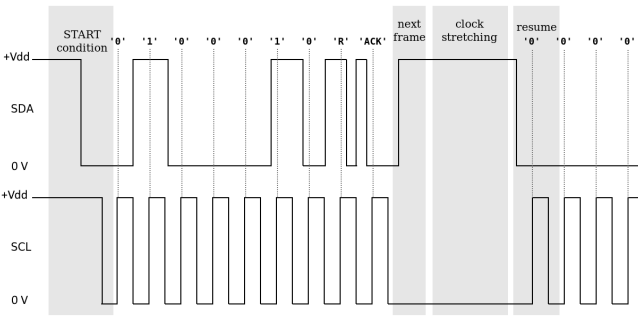
I2C의 독특한 특징은 slave의 클럭 늘리기(Clock stretching) 입니다.
- Master가 요청을 보냈는데, slave가 모종의 이유로 데이터를 아직 준비하지 못했다면, clock stretching을 사용해서 SCL을 `Low`로 유지해서 트랜젝션을 의도적으로 지연시킵니다.
- 하지만, Master는 계속해서 SCL을 `High`로 바꾸려고 시도할 것이므로 결국 데이터가 준비 됐을 때 `SCL = High`가 되며 트랜젝션이 재개됩니다.
- 이러한 I2C의 기능은 전송속도가 느린 주변기기와 통신할 때 아주 유용합니다.
Chapter 8. 저전력 최적화
8.1. 하드웨어 설계
- 주변장치가 한동안 사용되지 않는다고 판단됐을 때는, 풀다운 상태 (전압 low 상태)로 있도록 합니다.
- 주변장치의 전원이 꺼져도 다양한 원인으로 누설전류가 발생할 수 있으므로 최소화하는 회로 설계가 필요합니다.
- 이러한 '슬립 모드' 동안, passive 요소등을 잘 사용해서 회로가 확실하게 low 상태로 식별될 수 있도록 합니다.
- 디지텁 입출력핀의 '슈미트 트리거'(일정 threshold를 경계로 '0', '1' 딱딱 구분되도록 만들어주는 회로)가 외부 환경 및 전자기장 때문에 의도치않게 로직값을 갖거나 로직값이 변경되지 않도록 해야 합니다.
- 함수 호출 또는 인터럽트로 주변장치를 다시 사용하는 경우 정상으로 돌아오기 위한 wake-up 루틴을 구현합니다.
8.2. Clock 관리
- 사용하지 않는 내부 주변장치는 물론이고, 핵심 인터페이스도 clock을 꺼놓습니다.
- CPU의 전력은 clock에 비례하므로 성능과 에너지 사이에서 적절히 trade-off하며 PLL 레지스터를 제어해 주파수를 낮춥니다.
- 이때, 애플리케이션의 각 동작을 세부동작으로 구분한 뒤, 각 세부동작마다 적정한 clock을 할당합니다.
8.3. 의도적으로 낮은 전압 인가
- MCU의 동작전압은 의외로 넓은 편입니다. 시스템이 동작할 수 있는 수준에서 최소한의 전압을 전원에 인가하는 것도 방법입니다.
8.4. 적절한 저전력 모드 사용하기
MCU는 전력 소모 최적화를 위해 다양한 저전력 모드를 제공하는 경우가 많습니다.
- Sleep mode
- CPU의 clock이 비활성화 됩니다.
- 일반적으로 모든 주변장치는 정상작동 합니다.
- CPU가 실행되지 않기 때문에 상당향의 전력이 절약됩니다.
- 인터럽트를 통해 wake-up 됩니다.
- Deep sleep mode (= Stop mode)
- CPU뿐만 아니라 Bus의 clock도 비활성화됩니다.
- 모든 주변장치가 함께 꺼집니다.
- 주 전압 레귤레이터는 켜져있기 때문에 RAM과 레지스터는 값을 유지하고 있습니다.
- 외부 인터럽트를 통해 wake-up 됩니다.
- Stand-by mode
- 전압 레귤레이터조차 꺼지며 RAM과 레지스터도 값을 잃어버립니다.
- 마이크로와트 단위의 정말 최소한의 전력이 백업 회로를 유지하기 위해 사용됩니다.
- 사전에 정의된 wake-up 조건을 만족하거나, 외부 전력을 갖는 RTC로 wake-up 됩니다.
- 바로 상태가 재개되지 않고, 마치 재부팅하듯 리셋 핸들러부터 다시 시작합니다.
8.5. 정리
CPU와 버스는 항상 최대 주파수, 최고 clock으로 동작할 필요가 없습니다.
- 2개 이상의 CPU 주파수 변경 옵션을 애플리케이션의 세부 기능에 따라 분배하세요.
- 성능 위주 / 에너지 절감 위주로 번갈아가면서 그때그때 필요한 상태를 전환하는 것이 좋습니다.
- 센서 값이 들어온다면, 데이터를 읽고, 처리한 뒤 무선통신을 통해 외부로 전송하는 임베디드 SW가 있다고 가정합시다.
- 센서값이 들어올 때까지는 stand-by mode 또는 deep sleep mode로 대기합니다.
- 센서값이 들어와서 wake-up 했습니다, 데이터를 읽는 과정은 낮은 clock으로 해도 괜찮습니다.
- 데이터를 처리하고 무선통신으로 보내는건 CPU 처리를 많이 요구합니다. 따라서 최대주파수로 동작하도록 합니다.
대부분의 경우 sleep mode 또는 deep sleep mode 정도면 충분한 전력절감을 기대할 수 있습니다. Stand-by mode는 확실한 wake-up 방법과 시스템이 기존 상태에 의존성 없이, 재부팅해도 하나도 문제없는 경우에만 사용합시다.
Chapter 10. 병렬 태스크와 스케줄링
단일 코어 단일 CPU를 가지는 MCU는 한 번에 하나의 스레드를 실행합니다. 이런 환경에서 서로 다른 목적의 여러 기능을 실행하기 위해서는 적재적소에 골고루 실행해서 마치 병렬로 실행되는 것처럼 보이도록 해야 합니다. 이렇게 하나의 기능을 태스크(task)라고 부르며, 이 절에서는 각 태스크를 관리하고 교환하고 골고루 실행하는 방법을 배웁니다.
10.1. 태스크 블록 (Task Block)
태스크는 시스템 상에서 태스크 블록이라는 구조체 형태로 관리되고 표현됩니다.
태스크 블록에는 스케줄러에게 제공해야 할 태스크에 관한 거의 모든 정보가 포함돼있습니다.
- 태스크에 할당된 ID
- 태스크의 현재 상태
- 태스크가 실행하는 함수의 포인터
- 개별 스택 영역을 가리키는 포인터 및 스택포인터
- 태스크를 실행할 때 갖고있던 데이터 및 레지스터
- ...
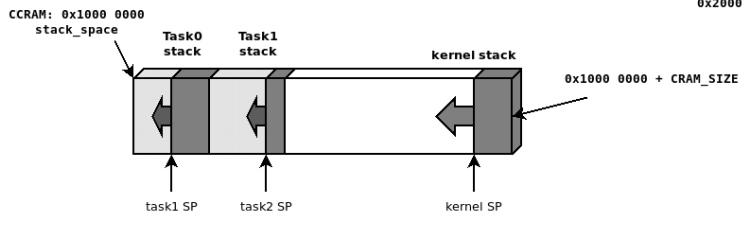
위 그림은 각 태스크마다 동일한 개별 스택 사이즈를 갖고 있는 가장 간단한 형태의 구조입니다.
특이한 점은, 빈 메모리의 가장 끝 주소에서 아래로 자라나는 기존의 스택 (위 그림의 'Kernel stack')과는 달리, 개별 태스크 스택은 전체 스택 영역의 하한선으로부터 시작합니다. 태스크 개별 스택은 자신만의 하한선이 있으며, 그로부터 스택 크기만큼 떨어진 곳을 스택포인터의 첫 주소로 둡니다. 따라서, 개별 스택 입장에서 보면 스택 포인터는 가장 높은 주소에서 하한선을 향해서 아래로 자라나므로 기존 스택 정책을 따르고 있습니다. 새로운 태스크가 할당된다면, 이전 태스크의 상한선을 하한선으로 갖는 새로운 스택이 할당됩니다.
이러한 메모리 레이아웃은 링커스크립트에서 직접 설정할 수 있습니다.
(e.g. 위 그림에서 CCRAM의 끝 지점 (`0x1000_0000`)부터 스택이 할당되는것도 링커스크립트에 기재됐기 때문입니다.)
10.2. 컨텍스트 스위칭 (Context Switching)
컨텍스트 스위칭은 현재 실행중인 태스크의 정보(+레지스터)를 개별 태스크 스택에 저장한 뒤, 다음 실행할 태스크의 값을 복구하는 일련의 과정을 말합니다. 이렇게 값을 복구하고 나면, 실행흐름은 완전히 이전 태스크에서 다음 태스크로 바뀌게 됩니다.
ARM은 컨텍스트 스위칭을 위해 레지스터를 메모리에 백업하고, 다시 복구하는 과정을 HW적으로 구현해놨습니다. 덕분에 컨텍스트 스위칭이 발생하면 레지스터의 복사본이 자동으로 현재 스택포인터가 가리키고 있는 곳에 push 됩니다. 이렇게 push된 레지스터의 복사본을 '스택 프레임(Stack Frame)'이라고 부르며 아래와 같이 구성돼있습니다.
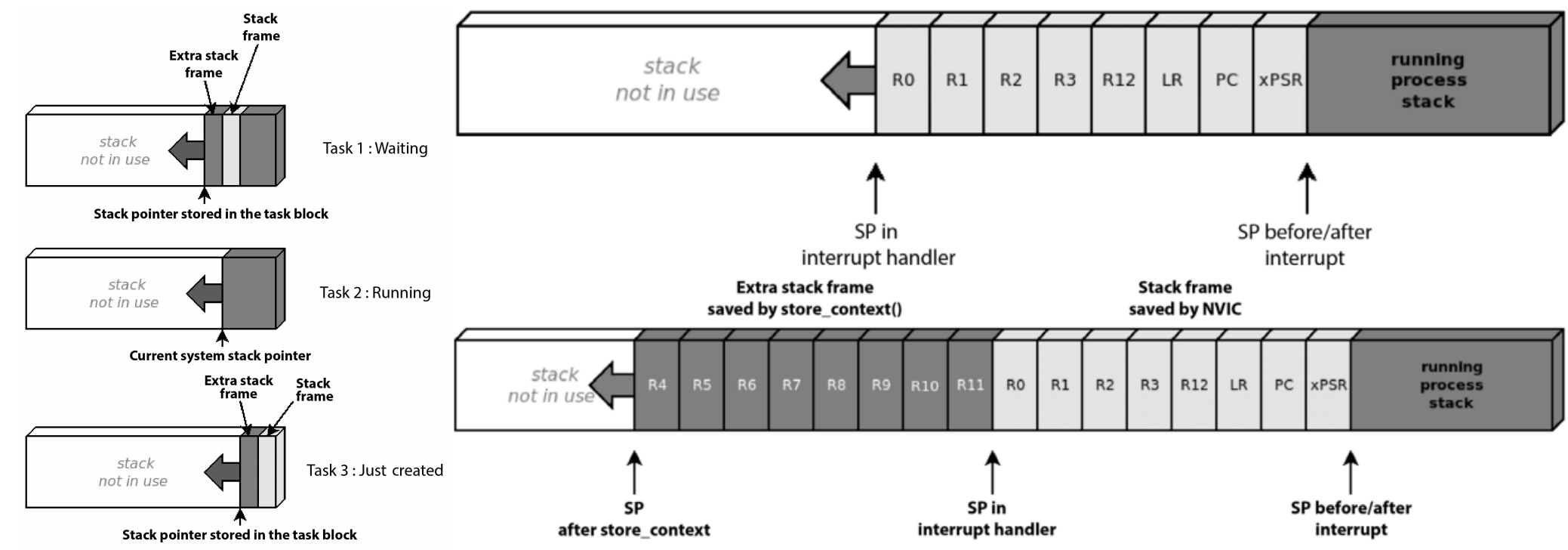
그러나 스택 프레임은 모든 레지스터를 저장하지는 않고, 상태레지스터(xPSR), PC, LR, R12, R0~3만 저장합니다.
APCS(ARM Procedure Call Standard)에서 중요한 역할을 갖는 레지스터들입니다. (※ 참고로 R0~3은 태스크 함수에 전달하는 인수를 포함하고 있습니다, `main()`의 `argc`, `argv`를 생각하면 됩니다. 그리고 R12는 LDM/STM 같은 연산을 위해 사용합니다.)
올바른 컨텍스트 스위칭을 하기 위해서는 나머지 레지스터의 정보들을 별개의 스택프레임에 따로 저장해야 합니다.
일반적으로 시스템 핸들러가 이 작업을 수행합니다. 코드는 아래와 같습니다.
static void __attribute__((naked)) store_context(void)
{
asm volatile("mrs r0, msp");
asm volatile("stmdb r0!, {r4-r11}");
asm volatile("msr msp, r0");
asm volatile("bx lr");
}
static void __attribute__((naked)) restore_context(void)
{
asm volatile("mrs r0, msp");
asm volatile("ldmfd r0!, {r4-r11}");
asm volatile("msr msp, r0");
asm volatile("bx lr");
}( 추가내용, `((naked))` 키워드)
- 앞서 태스크 단위에서의 컨텍스트 스위칭을 다뤘지만, 함수를 호출해서 흐름이 서브루틴으로 넘어갈 때도 컨텍스트 스위칭이 발생합니다.
- 기존 함수에서 진행하던 내용과 레지스터를 스택에 저장한 후
- PC가 새로운 함수로 바뀌면서 흐름이 서브루틴으로 넘어갑니다.
- 서브루틴이 종료되면, LR 레지스터 값을 PC로 가져와 복귀하면서
- 방금 스택에 백업해놨던 기존 함수의 실행 흐름을 다시 복원해 재개합니다.
- 함수의 호출과 반환에서 사용자가 눈치채지 못하지만 위와 같이 복잡한 과정이 일어납니다.
- 이러한 과정을 수행하기 위해서는 당연히 명령어가 필요하고, 컴파일러는 사용자 몰래 prologue, epilogue 라는 별명의 어셈블리 시퀀스를 삽입합니다.
- 자, 다시 위 코드를 보세요. 두 함수 `store_context()`, `restore_context()` 모두 `asm` 키워드를 이용해서 어셈블리 명령어를 호출하는 함수입니다. 게다가 그 내용은 태스크의 컨텍스트를 백업하고 복원하는 과정입니다.
- 즉, 저 두 함수 자체가 각각 prologue, epilogue나 마찬가지기 때문에 컴파일러에 의해 불필요하게 prologue, epilogue가 삽입될 필요가 없습니다.
- 단순히 오버헤드를 막고자 하는게 아닙니다. Prologue, epilogue 코드는 레지스터를 건드리는 어셈블리기 때문에, 우리가 저백업하고 복원할 태스크의 레지스터를 오염시킬 가능성이 있기 때문입니다.
10.3. 태스크 생성 및 초기화
struct stack_frame {
uint32_t r0, r1, r2, r3, r12, lr, pc, xpsr;
};
struct extra_frame {
uint32_t r4, r5, r6, r7, r8, r9, r10, r11;
};
static void task_stack_init(struct task_block *t) {
struct stack_frame *tf;
t->sp -= sizeof(struct stack_frame); // 개별 sp 초기화
tf = (struct stack_frame *)(t->sp);
tf->r0 = (uint32_t) t->arg; // r0~3
tf->pc = (uint32_t) t->start; // pc
tf->lr = (uint32_t) task_terminated; // LR
tf->xpsr = 0x01000000; // XPSR
t->sp -= sizeof(struct extra_frame); // 추가 프레임을 위해 SP 조정
}
struct task_block *task_create(char *name, void (*start)(void *arg), void *arg) {
struct task_block *t;
int i;
if (n_tasks >= MAX_TASKS)
return NULL;
t = &TASKS[n_tasks];
t->id = n_tasks++;
for (i = 0; i < TASK_NAME_MAXLEN; i++) {
t->name[i] = name[i];
if (name[i] == 0)
break;
}
t->state = TASK_WAITING;
t->start = start;
t->arg = arg;
t->sp = (uint8_t *)((&stack_space) + n_tasks * STACK_SIZE);
task_stack_init(t); // task_stack_init() 함수 여기서 호출
return t;
}위에서 배운 내용이 마치 그대로 적용된것 같은 태스크 생성 함수 `task_create()` 입니다. 내부에서 `task_stack_init()`을 호출해서 스택 프레임을 백업하는 것을 확인할 수 있습니다. 여기까지 포함해서 컨텍스트 스위칭의 순서는 다음과 같습니다.
- 현재 스택 포인터(SP 레지스터) 값을 현재 실행중인 태스크의 태스크 블록에 저장합니다.
- `store_context()`를 호출합니다. 스택프레임 및 추가 스택프레임을 스택에 push 합니다.
- 현재 태스크의 상태를 READY 상태로 변경합니다.
- 재개할 다음 새로운 태스크를 선택합니다. (스케줄러의 역할)
- 새로운 태스크의 상태를 RUNNING 상태로 변경합니다.
- 새로운 태스크의 태스크 블록에서 스택 포인터를 가져옵니다.
- `restore_context()`를 호출합니다. 스택프레임 및 추가 스택프레임을 pop 합니다.
10.4. 실시간 스케줄링
RTOS는 대부분의 운송 및 의료 산업에서 중요한 핵심 시스템을 구현하는 핵심 요소입니다. RTOS의 주요 요구사항 중 하나는 짧고 예상 가능한 시간 안에 관련 코드를 실행해 이벤트에 대응하는 능력입니다. 엄격한 타이밍 요구사항을 만족시키기 위해 각 태스크는 실행을 마쳐야할 deadline을 정확히 준수해야 하고, 공유자원을 이용한다면 세마포어, 뮤텍스를 사용해 다른 태스크와의 의존성 관련 요구사항도 만족해야 합니다. 그러므로 컨텍스트 스위칭은 빠르고 정확해야 하고, ISR은 될 수 있는 한 짧아서 오버헤드를 최소한으로 하고 인터럽트와 태스크에는 우선순위가 있어야 합니다.
엄격한 규율들을 지키며 태스크의 스케줄링을 하는 것은 대단히 복잡하고 어렵습니다. 시스템 응답속도를 최대로 유지하고, 우선순위가 낮은 태스크의 기아현상(starvation)을 방지하며 태스크의 반응시간을 최적화하기 위해 많은 스케줄러 정책이 연구됩니다.
- 가장 간단한 형태는 단순한 우선순위 기반 선점형 스케줄링입니다. 우선순위가 높은 태스크의 차레가 되면, 기존에 실행되고 있던 상대적으로 낮은 우선순위 태스크를 선점해버리고 컨텍스트 스위칭 후 실행됩니다.
- 마감 시간이 가장 가까운 태스크를 먼저 선택하는 '최단 마감 우선 (EDF, Earliest Deadline First)' 스케줄링 방법도 있습니다.
- 동일한 우선순위 끼리는 라운드로빈(Round-robin) 같은 타임 슬라이싱 방식을 사용합니다.
우선순위 기반 선점형 스케줄링은 분명히 간단하면서도 효과적인 방법이지만, 동기화 메커니즘과 경우에는 우선순위 도치(Priority Inversion)라는 문제 (설명링크) 가 발생할 수 있습니다.
'Embedded' 카테고리의 다른 글
| 임베디드 레시피 Chapter 4. ARM ② Assembly와 Bootloader (1) | 2025.01.29 |
|---|---|
| 임베디드 레시피 Chapter 3. SW ① 컴파일부터 로드 (0) | 2025.01.25 |
| 임베디드 레시피 Chapter 2. ARM (0) | 2025.01.20 |
| 임베디드 레시피 Chapter 1. HW ② 컴퓨터구성 (0) | 2025.01.19 |
| 임베디드 레시피 Chapter 1. HW ① 회로이론 (0) | 2025.01.18 |